
Les grandes entreprises technologiques dominent les investissements dans les technologies d’IA ; une stratégie publique de réglementation est essentielle pour lutter contre les inégalités dans la répartition du pouvoir économique.
Par Cecilia Rikap.
Original : Dynamics of Corporate Governance Beyond Ownership in AI, 2024.05.15
Résumé
Alors que l’engouement pour l’intelligence artificielle (IA) atteint son paroxysme, les géants de la technologie n’ont fait que renforcer leur emprise sur le développement et l’utilisation de ces nouvelles technologies. Cette emprise ne s’exerce pas seulement par le biais de l’acquisition de start-ups spécialisées dans l’IA, mais aussi, de plus en plus, par le biais de moyens alternatifs complexes.
Comme le montre ce rapport, les mécanismes en jeu sont les suivants :
- Utiliser le capital-risque des entreprises pour obtenir un accès préférentiel aux capacités, aux connaissances et aux informations et orienter la direction de la R&D des start-ups.
- Consolider une position dominante en fournissant des services cloud, ne laissant aux autres organisations d’autre choix que de payer les géants de la technologie. Cela inclut l’offre de crédits cloud qui incitent les start-ups et les universitaires à « dépenser » cet investissement de manière spécifique, par exemple en développant des applications basées sur des modèles d’IA appartenant aux géants de la technologie.
- La capture de la majorité des talents dans le domaine de l’IA, soit directement, soit indirectement, en rémunérant des universitaires pour qu’ils travaillent à temps partiel pour les Big Tech tout en conservant leur affiliation universitaire.
- Influencer l’orientation de la recherche en fixant les priorités lors de conférences et en façonnant la perception de ce qui est considéré comme la frontière de l’IA.
Si l’open source est parfois présenté comme un contrepoids aux Big Tech, il a également été récupéré : les entreprises de Big Tech ouvrent certaines parties de leurs logiciels ou modèles, comme lorsque Meta a rendu open source son modèle linguistique à grande échelle (LLM), Llama. Cela leur permet à la fois de bénéficier d’une communauté de développeurs prêts à travailler gratuitement sur le code et d’apporter des améliorations, mais aussi de faciliter la création d’applications par les développeurs sur leurs propres modèles et logiciels, ce qui renforce leur position dominante.
Ce qu’il faut, ce sont de véritables alternatives à l’IA à but lucratif, orientées vers les personnes et la planète. Cela doit s’appuyer sur l’ouverture des ensembles de données, y compris ceux des Big Tech, lorsque cela sert l’intérêt général, ainsi que sur la création d’un organisme de recherche public chargé de faciliter la collaboration à grande échelle.
1 Introduction : la saga OpenAI
Le 17 novembre 2023, Sam Altman, PDG et cofondateur d’OpenAI, a été licencié. Le scandale a pris une tournure inattendue lorsque Microsoft a proposé d’accueillir Altman et ceux qui souhaitaient quitter l’entreprise avec lui. Cette saga, qui s’est terminée par la réintégration de Sam Altman au poste de PDG le 22 novembre, a mis en évidence ce que le secteur technologique savait déjà : OpenAI est une filiale de Microsoft depuis 2019, date à laquelle Microsoft a investi son premier milliard de dollars dans cette start-up spécialisée dans l’IA.
En 2019, OpenAI était déjà un précurseur dans le domaine de l’IA, aux côtés de DeepMind. Cette dernière avait été rachetée par Google en 2014. En échange de son investissement, Microsoft a obtenu un accès privilégié aux grands modèles linguistiques (LLM) d’OpenAI et la possibilité d’orienter leurs travaux. Cela s’est accompagné d’un changement de statut juridique d’OpenAI, qui est passée d’une organisation à but non lucratif à une société à « profit plafonné », c’est-à-dire une société à but lucratif avec une limite sur le rendement des investissements. Ces changements ont conduit certains chercheurs d’OpenAI à démissionner et à créer Anthropic, une start-up désormais soutenue par Google.
OpenAI a lancé ChatGPT après une injection supplémentaire de 2 milliards de dollars et une pression de Microsoft pour qu’elle suspende le développement de LLM plus avancés afin de se concentrer sur une application de son modèle existant. Microsoft a eu accès à la technologie ChatGPT plusieurs mois avant sa sortie et l’a intégrée à ses logiciels avant ses concurrents.
L’énorme succès de ChatGPT a conduit Microsoft à s’engager à investir 10 milliards de dollars supplémentaires dans OpenAI. Aujourd’hui, Microsoft détient 49 % d’OpenAI. Plus l’activité de cette dernière est importante, mieux c’est pour Microsoft. Elle peut même vendre ChatGPT et d’autres logiciels en tant que service OpenAI à des entreprises concurrentes qui seraient plus réticentes à les acheter directement à Microsoft, comme Salesforce.
Investir dans OpenAI sans l’acquérir s’est avéré être une décision plus favorable pour Microsoft que l’acquisition de DeepMind par Google. Cela a permis à Microsoft d’élargir sa base de vente de services d’IA et, au moins jusqu’à la tentative de licenciement d’Altman, cela a détourné l’attention des régulateurs, apaisant les inquiétudes du public. Le PDG de Microsoft, Satya Nadella, a même déclaré publiquement que la nouvelle vague d’IA ne favorisait pas les acteurs historiques comme Microsoft, mais les nouveaux venus comme OpenAI, sans mentionner que ce dernier opère comme son satellite.
Pourquoi cette histoire est-elle pertinente au-delà des subtilités du monde de l’entreprise ? Que nous apprend-elle sur la gouvernance d’entreprise à l’ère numérique ? La première leçon est que contrôle et propriété ne vont pas de pair, comme nous l’expliquons plus en détail dans la section 2. La deuxième leçon est que, si les fusions et acquisitions restent importantes, le capital-risque des entreprises n’est pas seulement une stratégie visant à réaliser des gains financiers. Cela est expliqué dans la section 3, qui présente une analyse détaillée des investissements en capital-risque de certaines entreprises technologiques et examine de plus près qui finance les start-ups spécialisées dans l’IA. On peut encore soutenir que le capital-risque des entreprises est un moyen d’exercer un contrôle avec une propriété partielle, même si elle n’est pas totale. La section 4 se penche sur le « cloud public » en tant que domaine de contrôle au-delà de la propriété pour Amazon, Microsoft et Google. La section 5 analyse le rôle des géants technologiques dans la planification de l’IA de pointe. La section 6 examine si l’open source pourrait être une solution à la domination des géants technologiques. Ce rapport se termine par la section 7, qui propose quelques lignes directrices pour un développement et une utilisation de l’IA au service du bien public et de la nature, contre une IA qui renforce la polarisation, les inégalités et le contrôle des entreprises.
2 Contrôle au-delà de la propriété
Les discussions sur le contrôle et la propriété dans la gouvernance d’entreprise se concentrent généralement sur la relation entre la direction et les propriétaires. Cependant, dans le secteur technologique, il est de plus en plus courant de voir des entreprises technologiques cotées en bourse avec des actions à double classe de vote. Cela signifie que l’entreprise dispose d’au moins deux types d’actions. La seule différence entre ces deux types d’actions est que l’une d’elles confère plus de droits de vote par action et est réservée aux fondateurs, aux cadres supérieurs et parfois aux premiers investisseurs.
Alphabet, la société mère de Google, en est un exemple frappant. Ses actions de classe A donnent droit à une voix par action, ses actions de classe B donnent droit à dix voix par action et ses actions de classe C ne donnent aucun droit de vote. Au 31 décembre 2023, les fondateurs de Google détenaient 86,5 % des actions de classe B de leur entreprise, ce qui représentait 51,5 % du total des droits de vote, alors que les actions de classe B ne représentaient que 6,99 % du total des actions d’Alphabet.[1]
Meta, Palantir, Pinterest, Snap, Square et Zoom utilisent également un système à deux catégories d’actions, et l’introduction en bourse avec un système à deux catégories d’actions devient une stratégie de plus en plus courante parmi les entreprises technologiques. Les données de Jay Ritter sur les introductions en bourse depuis 1980 montrent que les cotations à double classe dans le secteur technologique sont restées inférieures à 15 % jusqu’en 2005, avant de passer à plus de 30 % de toutes les entreprises technologiques cotées en 2015. Dans les années 2020, ce chiffre est toujours resté supérieur à 40 %.
Les actions à double classe divisent les actionnaires entre une majorité qui détient la plupart des parts de l’entreprise mais qui a relativement peu, voire aucune, capacité de la contrôler, et une minorité dominante. Mais au-delà des relations entre les actionnaires, les fondateurs et les dirigeants, le contrôle peut également s’exercer au niveau organisationnel, certaines entreprises contrôlant la production et tirant des profits d’actifs qui appartiennent légalement à d’autres organisations.
Cette forme de contrôle trouve son origine dans la distinction entre propriété et accumulation qui est déjà implicite dans la forme juridique de la société. Depuis la fin du XIXe siècle, les sociétés peuvent détenir, en tout ou en partie, d’autres sociétés. En raison de la responsabilité limitée, la société mère n’est pas responsable des dettes de ses filiales, ni de celles de ses filiales, et ainsi de suite. Les multinationales ont été créées sous la forme de regroupements, pouvant compter jusqu’à plusieurs centaines, d’entités distinctes enregistrées dans différentes juridictions. Les entreprises en tant qu’entités juridiques ont toujours été différentes du concept économique d’entreprise multinationale unique. D’un point de vue juridique, la multinationale en tant qu’entité unique n’a jamais existé, même si le siège social exerce un contrôle unifié sur toutes les filiales.[2]
Si la société mère est le propriétaire ultime d’au moins une partie des actions des autres entités, d’autres formes de contrôle de différentes organisations ou entités juridiques au-delà de la propriété ont émergé depuis les années 1970, soutenues par la concentration des actifs incorporels. Le franchisage est une pratique courante de contrôle au-delà de la propriété qui s’est développée dans le secteur de l’hôtellerie. Le franchiseur est propriétaire des marques, souvent protégées par des marques déposées, ainsi que des pratiques commerciales, des machines brevetées et des dessins et modèles enregistrés. Tout cela est imposé aux franchisés à des prix fixés par le franchiseur, qui prélève également une part du chiffre d’affaires brut de chaque franchisé.[3]
Les chaînes de valeur mondiales fonctionnent selon des principes similaires, même si l’apparence de chaque entreprise est différente. Elles sont régies par des sociétés de premier plan qui concentrent les connaissances exclusives sur la manière de réintégrer la chaîne (c’est-à-dire qui peut faire quoi et comment) et capturent la valeur sous forme de rentes intellectuelles payées par ceux qui s’intègrent dans la chaîne à des positions subordonnées.[4] La relation entre les entreprises de plateforme et les complémentaires — tels que les développeurs d’applications et les fournisseurs de services cloud — reproduit le même schéma. La plateforme ne se contente pas de capturer de la valeur, elle définit également comment les applications ou les services doivent être produits et tarifés en fonction de son contrôle sur des actifs incorporels essentiels (voir section 4).
Dans toutes ces architectures, les entreprises subordonnées accumulent du capital en partie pour le compte de la société dominante qui s’est assuré un accès privilégié aux actifs immatériels nécessaires à l’ensemble du processus de production. Ces leaders gèrent et organisent les flux d’informations et de connaissances entre les parties. En règle générale, ils externalisent également certaines étapes de la production de nouvelles connaissances à d’autres institutions (universités, start-ups, etc.) tout en conservant le contrôle sur la manière de recombiner et de donner un sens à tous ces éléments. Dans l’ensemble, les connaissances sont produites par un grand nombre, mais quelques-uns récoltent de manière disproportionnée les profits associés, captés auprès d’autres organisations et consommateurs sous forme de rentes intellectuelles.
Les rentes intellectuelles sont des profits extraordinaires qui sont censés durer jusqu’à ce que les acteurs du même secteur adoptent l’innovation qui les a générés ou qu’une autre (nouvelle) entreprise innove et prenne la tête. Cependant, la rente intellectuelle est renforcée par le secret (comme dans le cas des mégadonnées et des algorithmes tenus secrets) et les droits de propriété intellectuelle (DPI). Nous parlons de monopolisation intellectuelle pour décrire la perpétuation d’une pratique dans laquelle de nombreux acteurs co-créent de la valeur et co-produisent des connaissances qui finissent par être captées de manière disproportionnée par quelques géants.[5] La concentration économique des monopoles intellectuels repose sur leur concentration de ces actifs incorporels. En termes simples, il s’agit d’entreprises qui accumulent des richesses considérables en transformant les connaissances et les données coproduites avec (ou par) de nombreux autres acteurs en actifs incorporels qui leur sont propres. C’est précisément ce qui se passe avec l’IA.
3 Capital-risque d’entreprise
Google, Microsoft et Amazon investissent activement dans des centaines de start-ups, en donnant la priorité à l’IA. En 2023, ils ont injecté plus d’argent dans le monde des start-ups spécialisées dans l’IA que n’importe quel capital-risqueur. Ensemble, ils ont investi les deux tiers des 27 milliards de dollars levés. Ces entreprises investissent dans un large éventail d’applications de l’IA : les grandes entreprises technologiques contrôlent au moins en partie les start-ups. La place de ces géants dans l’ensemble du système de capital-risque en termes de nombre d’entreprises financées est évidente dans le réseau des bailleurs de fonds qui apparaissent le plus fréquemment parmi les cinq premiers investisseurs de chaque entreprise d’IA ayant bénéficié d’investissements en capital-risque depuis la sortie de ChaptGPT (voir figure 1, plus d’informations sur le capital-risque d’entreprise et une note méthodologique présentée à la fin du rapport). La figure 1 fournit également des informations sur les technologies les plus fréquemment développées par les entreprises financées par chaque groupe d’investisseurs.
La figure 1 ne fournit pas d’informations sur les montants investis, mais montre l’influence généralisée des grandes entreprises technologiques. Ces entreprises ne concentrent pas leurs investissements sur quelques start-ups seulement ; au contraire, la figure 1 montre qu’à l’exception des groupes spécialisés dans les applications de l’IA pour les soins de santé, au moins un géant technologique est présent dans chaque groupe, ce qui indique qu’ils contrôlent la plupart des start-ups du secteur de l’IA.
À en juger par l’orientation des entreprises financées dans chaque groupe, les grandes entreprises technologiques s’intéressent davantage au contrôle des entreprises qui développent des technologies d’IA fondamentales ou plus génériques et celles qui travaillent sur des applications pour des secteurs autres que la santé, tels que les énergies renouvelables, les villes et bâtiments intelligents, la robotique et les semi-conducteurs. Samsung privilégie les investissements dans les entreprises travaillant sur l’IA et les semi-conducteurs, SAP favorise les entreprises qui appliquent l’IA aux énergies renouvelables et le géant chinois Tencent investit davantage dans les entreprises qui développent l’automatisation et la robotique. Microsoft, tout comme Intel et Nvidia, continue de se concentrer sur le financement de l’apprentissage automatique à usage général. Google et Amazon préfèrent quant à eux les entreprises d’IA travaillant sur des applications pour l’éducation et la blockchain. Pour plus d’informations sur le réseau de capital-risque des entreprises, voir le graphique et la note méthodologique à la fin du présent rapport.
Dans l’ensemble de l’échantillon analysé des entreprises d’IA ayant bénéficié de capital-risque depuis la sortie de ChatGPT, Google se classe troisième en termes de nombre d’entreprises financées (voir tableau 1). Seuls l’investisseur en préamorçage Techstars et l’accélérateur Y Combinator devancent Google, Y Combinator investissant principalement dans des start-ups d’IA en dehors des domaines d’intérêt des grandes entreprises technologiques (voir sa place dans la figure 1), tandis que Techstars finance principalement des entreprises travaillant sur l’IA appliquée plutôt que sur des modèles généraux ou fondamentaux.
Table 1: Top 25 AI Start-Up Investors
| Funder | Number of AI funded companies |
|---|---|
| Techstars | 253 |
| Y Combinator | 207 |
| 136 | |
| Plug and Play | 101 |
| Antler | 73 |
| Alumni Ventures | 73 |
| Sequoia Capital | 67 |
| Innovate UK | 59 |
| Creative Destruction Lab (CDL) | 51 |
| Microsoft | 50 |
| Andreessen Horowitz | 50 |
| Intel | 44 |
| National Science Foundation | 44 |
| MassChallenge | 43 |
| Gaingels | 43 |
| Amazon | 39 |
| TIPS Program | 38 |
| Khosla Ventures | 36 |
| Insight Partners | 36 |
| 500 Global | 35 |
| European Innovation Council | 34 |
| NVIDIA | 32 |
| Bpifrance | 30 |
| Pioneer Fund | 29 |
| Entrepreneur First | 27 |
Source: Author’s analysis based on Crunchbase. Data retrieved by February 2024 for all the companies that received funding since the release of ChatGPT.
Microsoft occupe la dixième place du tableau 1. À en juger par les raisons invoquées récemment pour confirmer son investissement dans la start-up française Mistral, spécialisée dans l’IA, qui évoquait la diversification des investissements dans les start-ups de l’IA comme un moyen de compenser sa participation importante dans OpenAI, il est fort probable que Microsoft grimpe dans ce classement à court terme. Mistral, loin d’être un acteur indépendant avant de conclure un accord avec Microsoft, comptait déjà Nvidia et Salesforce parmi ses principaux bailleurs de fonds. Entre Google et Microsoft, les principaux investisseurs en capital-risque, dont Sequoia Capital, occupent la majeure partie du reste du classement des principaux bailleurs de fonds. Le seul exemple de financement public des entreprises d’IA dans le top 10 est celui de l’agence nationale britannique pour l’innovation, Innovate UK.
En bref, les acquisitions ne sont pas le seul moyen pour les grandes entreprises technologiques d’accéder aux actifs incorporels et aux talents des start-ups tout en tenant à distance leurs rivaux potentiels. Une forme de domination plus cachée mais très répandue consiste à utiliser le capital-risque des entreprises pour obtenir un accès préférentiel aux capacités, aux connaissances et aux informations, ainsi que la possibilité d’orienter la recherche et le développement des start-ups. Tout comme les acquisitions, il s’agit d’un mécanisme utile pour obtenir des rendements futurs potentiels sur ces investissements tout en empêchant les start-ups de devenir des rivales. Dans une certaine mesure, cela rejoint le point de vue d’Andrew Ng, associé directeur général de la société de capital-risque AI Fund, ancien fondateur de Google Brain et directeur scientifique en intelligence artificielle chez Baidu. Il explique dans de nombreuses conférences que ses investissements se concentrent principalement sur la couche applicative, qui dépend essentiellement des grandes entreprises technologiques bien établies et se développe au sein de leurs clouds (voir section 4). En fait, l’analyse des start-ups spécialisées dans l’IA permet de conclure que la plupart d’entre elles appliquent l’IA plutôt que de développer des modèles de base qui entreraient en concurrence avec les grandes entreprises technologiques.
En devenant investisseurs, les grandes entreprises technologiques peuvent également entrer en contact direct avec le ou les fondateurs ou le PDG d’une start-up. Cela leur est utile si elles envisagent de devenir des clients ou des fournisseurs de grande valeur, en utilisant les fonds pour intégrer rapidement la start-up dans leur sphère d’influence. Nvidia et les trois géants du cloud peuvent ainsi faire d’une pierre deux coups en récupérant l’argent lorsque l’entreprise investit dans des infrastructures, c’est-à-dire en achetant des GPU Nvidia ou en louant directement des GPU tout en utilisant d’autres services des clouds des Big Tech.
4 Contrôle depuis les nuages
Les investissements de Microsoft dans OpenAI ne se sont pas limités à des injections de capitaux. Une partie de l’argent a été versée sous forme de crédit cloud pour la puissance de traitement. Depuis 2019, le cloud Azure de Microsoft forme et exécute les modèles d’OpenAI. Phil Waymouth, directeur principal des partenariats stratégiques chez Microsoft, a déclaréaprès le succès de ChatGPT que cette avancée avait été rendue possible grâce au « passage de la recherche à grande échelle dans les laboratoires à l’industrialisation de l’IA ». L’IA n’est pas seulement constituée de code ou d’algorithmes ; elle est le résultat de la combinaison de données, de code et de puissance de calcul. L’IA n’existe pas si l’un de ces trois éléments fait défaut, et la majeure partie de la puissance de calcul est concentrée entre les mains de trois géants américains du cloud.
Contrairement à ce que son nom pourrait laisser croire, le cloud public est une activité privée très concentrée et très rentable. Amazon AWS, Microsoft et Google contrôlent respectivement 65 % du marché mondial du cloud computing. AWS est en tête avec une part stable de 32 à 34 %, tandis que Microsoft et Google ont récemment connu une croissance plus rapide que le cloud d’Amazon, au détriment d’autres petits acteurs. Entre 2017 et 2023, la part de marché de Microsoft est passée de 12 à 13 % à 22 % du marché mondial. Google a également presque doublé sa part de marché, atteignant 11 % du marché en 2023. En conséquence, les revenus de Google Cloud ont doublé entre 2020 et 2022. Si AWS est l’activité la plus rentable d’Amazon, Google affiche toujours un déficit pour son cloud, en partie en raison des efforts de l’entreprise pour maintenir des prix bas afin de conquérir des parts de marché. Les seuls grands fournisseurs de cloud computing en dehors des États-Unis se trouvent en Chine, où Alibaba est le quatrième fournisseur mondial.
Le cloud public est une architecture d’externalisation mondiale dans laquelle les organisations paient pour accéder à un service informatique. De manière générale, quatre types de services sont proposés sur le cloud : les logiciels en tant que service (SaaS), les plateformes en tant que service (PaaS), l’infrastructure en tant que service (IaaS) et les données en tant que service (DaaS). Les organisations de toutes tailles et de tous secteurs, des start-ups aux grandes entreprises, transfèrent de plus en plus leurs opérations informatiques vers le cloud ; d’ici 2025, 45 % du stockage mondial de données se fera dans le cloud.
La migration vers le cloud est motivée par le fait qu’il transforme ce qui pourrait être une dépense d’investissement importante en un coût variable et extrêmement flexible. L’IaaS signifie que les entreprises et autres organisations paient pour ce qu’elles consomment en termes de stockage et de puissance de traitement, qui varie en fonction des cycles macroéconomiques et des cycles spécifiques à leur activité et à leur secteur. Si ces services déconcentrent le capital tangible pour la plupart, ils entraînent une plus grande concentration des actifs tangibles pour Amazon, Microsoft et Google. Selon les données de Bloomberg pour 2021, les dépenses d’investissement dans le cloud de ces entreprises représentaient entre 9 et 12 % de leurs revenus liés au cloud. Ces géants du cloud ont cloisonné des espaces numériques et tirent une rente d’infrastructure de la location de leur utilisation. Cela peut être comparé aux loyers perçus par les propriétaires fonciers urbains et ruraux.[6]
L’IaaS est déjà une activité très lucrative, qui se développe parallèlement aux autres services cloud. Le coût supplémentaire lié à la vente d’un SaaS à un autre client (son coût marginal) est proche de zéro, car les mêmes lignes de code sont vendues à l’infini. Le prix reflète essentiellement une rente intellectuelle tirée du secret du code.
Les géants du cloud proposent dans leurs clouds des ensembles croissants de services d’IA qui facilitent le développement d’applications spécifiques à ce domaine. Ces services accélèrent et facilitent l’adoption de l’IA, mais la rendent également plus risquée. Lorsque les produits SaaS sont des algorithmes d’apprentissage automatique (y compris l’IA générative de pointe qui alimente les chatbots intelligents), plus ils sont prêtés, plus ils traitent de données, ce qui leur permet d’apprendre, de s’améliorer et de renforcer le leadership numérique des géants du cloud. En effet, l’apprentissage automatique est aujourd’hui synonyme d’apprentissage profond, une approche de l’IA dans laquelle l’algorithme s’améliore (fait de meilleures prédictions) à mesure qu’il traite davantage de données.[7]
Pour les organisations qui ne peuvent pas ou ne souhaitent pas former leurs propres modèles, les géants du cloud proposent également des modèles de machines virtuelles préconfigurés pour former les algorithmes d’IA. Microsoft a utilisé les capacités de calcul d’OpenAI pour améliorer les environnements de formation d’Azure, développant une solution standardisée désormais proposée à d’autres clients sous forme de service pour la formation et l’utilisation de chatbots et d’autres solutions d’IA personnalisées.
Les clouds publics proposent également des outils DaaS et de préparation des données qui mettent les données dans un format adapté au traitement par des algorithmes. Le DaaS désigne l’accès à des bases de données standardisées, telles que des ensembles de données d’images ou de textes. AWS héberge une place de marché pour les données appelée Data Exchange, qui proposait en novembre 2023 plus de 3 500 ensembles de données provenant de plus de trois cents fournisseurs. Comme pour le code, un même ensemble de données peut être vendu à plusieurs reprises sans travail supplémentaire important.
Le principe du SaaS, du DaaS et du PaaS est toujours le même : vendre chaque service autant de fois que possible à un prix qui reflète principalement un loyer. Un autre avantage pour les géants du cloud est que, à l’exception des solutions open source proposées en tant que service cloud, tous ces services sont des boîtes noires. Les entreprises qui utilisent ces services ne peuvent pas apprendre en utilisant ces technologies numériques, car elles ne paient que pour l’utilisation, et non pour l’accès aux éléments intangibles sur le cloud.
Alors, pourquoi les start-ups et autres entreprises migrent-elles vers ces clouds ou développent-elles directement leurs solutions sur ceux-ci ? Pour les start-ups, le cloud n’est pas seulement synonyme de flexibilité face aux incertitudes économiques. Elles ne disposent pas non plus des fonds nécessaires pour investir dans un centre de données et employer du personnel chargé de la maintenance et du codage des éléments plus généraux nécessaires au fonctionnement de leurs solutions spécifiques. Dans d’autres cas, elles ont du mal à trouver les personnes capables de développer une IA de pointe (voir section 5).
La prolifération des start-ups à travers le monde repose précisément sur la mise à disposition de différents éléments informatiques sous forme de services, car cela réduit les barrières à l’entrée. L’inconvénient est que toutes ces start-ups naissent avec l’obligation de payer un loyer à vie. L’ensemble de leur activité dépend strictement des géants de la technologie et, contrairement aux acteurs plus importants qui peuvent explorer et explorent des alternatives pour contrebalancer la domination de ces entreprises géantes,[8] les start-ups n’ont aucune issue.
Ce problème est encore plus aigu lorsque les start-ups vendent leurs offres sous forme de services cloud, ce qui entraîne des frais supplémentaires. Sur AWS Data Exchange, par exemple, les entreprises doivent payer des frais chaque fois que leurs services sont achetés. En janvier 2023, la place de marché AWS comptait 6 783 partenaires enregistrés associés à 178 qualifications (catégories spécifiques de services cloud dans le cadre du SaaS, du PaaS, etc.).[9] Ceux qui proposent leurs services sur ces places de marché sont appelés « partenaires » par les géants du cloud, mais leur relation est tout sauf un partenariat entre égaux. Ces partenaires sont pour la plupart des petites entreprises, mais on trouve également de grandes multinationales, comme Hitachi et IBM, et de grandes sociétés de conseil, comme Accenture et Deloitte, qui proposent également des services cloud sur les plateformes des Big Tech.
Barracuda Networks, une société de logiciels de cybersécurité, a été la première à proposer des services SaaS sur la place de marché AWS. En 2023, elle proposait 49 produits différents sur ce cloud. À l’autre extrémité du spectre, 2 374 entreprises n’offrent qu’un seul service informatique sur AWS. Comme la plupart de ces entreprises ne vendent que des services informatiques, leur chiffre d’affaires dépend entièrement des Big Tech.
Amazon, comme les autres géants du cloud, dicte chaque mouvement des fournisseurs de services cloud sur AWS, même s’il s’agit d’entreprises officiellement indépendantes. Amazon définit les règles à suivre pour fixer les prix et fixe les augmentations maximales annuelles. Les changements de prix doivent être examinés et approuvés par Amazon. Le processus prend entre un et trois mois. AWS recommande également comment et quand facturer l’utilisation d’un service.[10] Cela comprend la fourniture de contrats de licence standardisés à signer chaque fois qu’un client achète un service avec un prix contractuel sur sa place de marché. Un contrat de prix consiste en un prix initial payé par les clients pour acheter l’utilisation d’un service (une licence) pendant une période déterminée. Et, comme sur la place de marché électronique d’Amazon, la mise en vente d’un produit sur la place de marché AWS est gratuite, mais des frais de transaction de 30 % sont facturés.
Il existe également une forte complémentarité entre les différents types de services cloud, ce qui favorise encore davantage les Big Tech. Les données stockées dans le cloud doivent être traitées, ce qui nécessite une puissance de calcul (un service cloud distinct) et des algorithmes. Si les entreprises peuvent écrire leurs propres algorithmes pour ces derniers et les exécuter sur le cloud, elles écrivent le plus souvent le code en intégrant des SaaS génériques proposés sur le cloud. De même, si une entreprise souhaite utiliser un SaaS, elle devra le faire sur le cloud, ce qui implique également de consommer, et donc de payer, de la puissance de calcul. En termes de tarification, l’IaaS est relativement plus cher, en particulier pour le traitement des mégadonnées, tandis que le SaaS et le DaaS sont moins chers, voire gratuits dans certains cas, comme je l’explique ci-dessous. Il s’agit d’une stratégie commerciale et marketing particulièrement avantageuse pour les géants technologiques, car ils possèdent l’infrastructure et conservent ainsi tous les bénéfices des services les plus chers, tandis qu’une partie du SaaS et du DaaS est souvent développée par des acteurs tiers qui ne versent aux géants technologiques que des commissions sur les transactions.
Crédits cloud : un verrouillage déguisé en capital-risque
Les géants du cloud offrent des services cloud gratuits pour attirer davantage de clients. En 2023, AWS proposait dix services gratuits d’apprentissage automatique pendant une durée comprise entre 1 et 12 mois. Ces services allaient de la conversion de texte en parole et vice versa à la création et au déploiement de modèles d’apprentissage automatique. AWS propose toujours Amazon Rekognition, un outil de reconnaissance faciale qui, en 2019, s’est avéré présenter des biais raciaux et sexistes.
Les crédits peuvent être interprétés comme des fonds providentiels ou du capital-risque destinés à des usages spécifiques, incitant les nouvelles entreprises à travailler sur le SaaS et, plus récemment, à créer des applications d’IA sur la base des modèles contrôlés par les géants de la technologie et leurs filiales. Ces bons informatiques favorisent la migration vers le cloud. Pour une entreprise de la taille d’Amazon, Microsoft ou Google, élargir son marché en offrant des crédits à des start-ups qui non seulement utilisent leur cloud, mais finiront probablement par offrir leurs services sur leurs clouds, est à la fois une source de revenus directs et une consolidation à long terme, car plus le marché est grand, plus les entreprises sont susceptibles de choisir ce cloud. AWS organise également des concours pour les start-ups et finance les gagnants avec des crédits cloud supplémentaires.
Un type spécifique de crédit cloud est proposé aux universitaires pour le traitement de données avec l’IA ou l’utilisation d’autres services informatiques. Le programme AWS Cloud Credit for Research, comme son nom l’indique, accorde des crédits cloud gratuits pour mener un projet de recherche utilisant AWS. En 2018, dernière année pour laquelle des informations publiques sont disponibles, Amazon a accordé 387 de ces crédits à 216 organisations. Ceux-ci étaient très concentrés : 49 crédits ont été accordés à l’université de Californie et 32 à Harvard. Seules neuf organisations ont reçu cinq crédits ou plus. Outre les universités, d’autres organismes de recherche publics ont également recours au cloud : la National Science Foundation américaine a mis en place une stratégie multicloud pour héberger ses recherches, mais privilégie néanmoins les géants américains de la technologie comme seuls fournisseurs agréés. L’UE a également fini par s’associer à des géants américains de la technologie pour développer un cloud européen basé sur GaiaX, l’infrastructure de données fédérée de l’Europe. Reste à voir si l’AI Research Resource britannique sera indépendante des géants du cloud. Ce qui est clair, c’est que les 300 millions de livres sterling engagés par le gouvernement britannique pour cette installation représentent environ la moitié de ce que Google dépensait par centre de données en 2022.
De plus, AWS a lancé des appels à candidatures spéciaux pour les institutions des pays semi-périphériques. Elle a signé des accords avec le Conseil national de la recherche argentine (CONICET), la Pontifica Universidad Católica del Perú et le Conseil national du développement scientifique et technologique brésilien (CNPq) pour des appels à propositions de recherche conjoints. Si les entreprises locales d’Amérique latine ont tendance à être (très) tardives dans l’adoption des nouvelles technologies, les principaux établissements universitaires disposent d’équipes à la pointe de la recherche mondiale dans leurs domaines, qui sont actuellement encouragées à développer l’IA.
Les crédits cloud représentent un coût supplémentaire extrêmement faible pour les Big Tech. La plupart des services informatiques sont constitués des mêmes lignes de code propriétaire qui peuvent être revendues plusieurs fois. En termes de puissance de traitement ou de capacité de stockage, le fait que de petits projets ne consomment qu’une infime partie de l’infrastructure colossale des Big Tech représente un coût d’opportunité très faible. De plus, les crédits cloud permettent à Amazon, Microsoft et Google d’identifier, et donc d’acheter ou de copier, les projets qui ont du succès.
5 Contrôle des Big Tech sur la recherche en IA
Comme mentionné ci-dessus, l’IA repose sur une combinaison de données, de puissance de calcul et de code ou d’algorithmes. Tous ces éléments sont contrôlés par les Big Tech. Alors que les Big Tech ont librement récolté les données de la société à partir de leurs plateformes et d’autres sources (voir la section 7 sur la manière dont elles ont accédé aux données publiques sur la santé) et ont concentré la plupart de la puissance de calcul dans leurs clouds, le code n’est pas uniquement produit dans les laboratoires de R&D des Big Tech. Le codage désigne généralement l’écriture d’algorithmes mathématiques avancés. Ces modèles ou algorithmes sont des ensembles de règles ou d’instructions à suivre pour résoudre des problèmes ou effectuer un calcul.
Bien que leurs activités d’origine diffèrent, la recherche et le développement (R&D) des grandes entreprises technologiques américaines se concentrent de plus en plus sur l’amélioration des modèles d’IA. Dès 2017, Amazon était l’entreprise qui offrait le plus grand nombre d’emplois dans le domaine de l’IA aux États-Unis, suivie par Nvidia et Microsoft. Les Big Tech sont en tête du classement mondial des dépenses d’entreprise en R&D (BERD) ; seuls les États-Unis et la Chine ont des dépenses publiques en R&D supérieures à celles de chacune des cinq grandes entreprises technologiques américaines (Amazon, Alphabet (Google), Meta, Microsoft et Apple, par ordre de BERD) (les données BERD sont disponibles auprès de la Commission européenne, Centre commun de recherche, 2023).[11]
Les scientifiques et ingénieurs en IA travaillant pour les Big Tech peuvent être considérés comme un pont entre la coproduction et l’appropriation de l’IA, car les Big Tech ne se contentent pas de développer l’IA en interne, mais collaborent également avec des universités, des organismes de recherche publics et d’autres entreprises dans le cadre de projets de recherche communs. Ces collaborations donnent lieu à des milliers d’articles co-rédigés, mais seulement à une douzaine de brevets détenus en copropriété, car la plupart des milliers de brevets des Big Tech sont détenus en exclusivité (Rikap & Lundvall, 2020, 2022).[12]
Souvent, les talents en IA sont drainés hors du monde universitaire. Gofman et Jin ont constaté une fuite des cerveaux importante et exponentielle des professeurs d’IA des universités américaines et canadiennes vers l’industrie, Google, Amazon et Microsoft étant les entreprises qui embauchent le plus grand nombre de chercheurs en IA, suivies par Meta, Uber et Nvidia.[13] Meta a même continué à embaucher des personnes pour des postes liés à l’IA tout en procédant à des licenciements massifs.[14]
Alors que les jeunes scientifiques de renom acceptent généralement des emplois à temps plein dans les grandes entreprises technologiques après leur doctorat ou leur post-doctorat, plusieurs chercheurs chevronnés ont obtenu un accord plus avantageux : ils restent affiliés à leur institution universitaire, conservant ainsi leur prestige et les étudiants qui travaillent avec eux et leur apportent des idées nouvelles, et se voient offrir une rémunération mirobolante pour travailler également à temps partiel pour une grande entreprise technologique. L’analyse d’un échantillon de toutes les présentations faites lors des 14 conférences les plus prestigieuses sur l’IA entre 2012 et 2020 a révélé qu’une centaine d’universités et d’organismes de recherche publics comptaient des chercheurs ayant une double affiliation avec Amazon, Microsoft, Google ou Meta. Ceux-ci étaient principalement concentrés aux États-Unis, mais des institutions européennes, chinoises, canadiennes, hongkongaises et israéliennes comptaient également des chercheurs ayant conclu de tels accords. Par rapport aux autres grandes entreprises technologiques, Google et Microsoft comptent davantage de ces doubles affiliations.[15]
Cela permet aux entreprises de la Big Tech de contrôler la recherche en IA. À en juger par les citations, Jurowetzki et al. ont observé que Microsoft et Google sont les organisations les plus influentes dans la communauté de la recherche en IA.[16] Plus généralement, Klinger et al. ont constaté que la recherche en IA menée par le secteur privé, en particulier par les géants technologiques spécialisés dans ce qu’ils ont défini comme des « méthodes d’apprentissage profond gourmandes en données et en calcul », guide l’ensemble de la communauté de l’IA.[17]
Depuis 2012, les Big Tech, en particulier Google et Microsoft, participent de plus en plus aux grandes conférences sur l’IA. Elles sont en tête en termes de nombre de présentations, de nombre d’autres organisations co-auteurs de leurs recherches et, plus généralement, de leur place dans le réseau mondial de co-auteurs qui en résulte. L’une des motivations de leur participation active à ces événements universitaires est d’identifier et de recruter des scientifiques spécialisés dans l’IA. Une autre motivation est la capacité à orchestrer ce que les organisations du monde entier perçoivent comme la frontière de l’IA, encourageant l’ensemble du domaine à travailler sur les priorités des grandes entreprises technologiques.
L’analyse du réseau montre à quel point les grandes entreprises technologiques sont devenues centrales dans la définition des termes de la recherche en IA. Si l’on examine le réseau des organisations qui ont présenté le plus souvent des recherches lors de conférences sur l’IA entre 2018 et 2020 (dernière période de mon échantillon), Google et Microsoft apparaissent comme jouant le rôle d’intermédiaire le plus important, avec la capacité d’influencer des organisations qui ne collaborent pas directement avec elles, mais avec d’autres qui ont des liens directs, ou d’autres qui sont liées à des organisations qui co-rédigent avec les Big Tech. Occupant des positions relativement moins importantes, Amazon, Meta et plusieurs grandes entreprises technologiques chinoises renforcent également leur présence et leur centralité dans le réseau au fil du temps.[18]
Les grandes entreprises technologiques américaines sont également très bien représentées dans les comités de ces conférences. NeurIPS, la principale conférence annuelle sur l’apprentissage automatique, en est un exemple extrême. Chaque Big Tech compte au moins un membre dans son comité d’organisation. Google, qui a obtenu le plus grand nombre d’articles acceptés lors de cette réunion académique en 2022,[19] comptait neuf des 39 membres du comité. En rejoignant ces comités, les géants de la technologie peuvent définir quels articles seront acceptés ou remporteront des prix, ce qui témoigne de leur pouvoir d’influencer le domaine. Partout où l’on regarde, les Big Tech contrôlent le système d’IA.
6 L’open source est-il la solution ?
On pourrait considérer l’open source comme une alternative possible à la position bien établie des Big Tech dans le domaine de l’IA. L’open source est un moyen de produire des connaissances de manière collaborative et volontaire, au profit de l’ensemble des communautés. Il est né de la nécessité de renverser la privatisation et la marchandisation des connaissances par des géants tels que Microsoft et IBM dans les années 1980 et 1990.
Le copyleft (par opposition au copyright) est un système de licence qui stipule que tout logiciel utilisant et adaptant un logiciel libre doit également être libre, ce qui signifie qu’il ne peut pas être intégré dans un logiciel payant.[20] Mais lors d’un sommet sur les logiciels libres, ce mouvement a voté en faveur de l’« open source » comme nouveau nom, réduisant ainsi la portée des logiciels libres. L’idée de l’open source a ouvert la voie à différentes alternatives au copyright qui ne vont pas aussi loin que le copyleft. La plus populaire est Apache, qui est plus favorable aux entreprises car, contrairement au copyleft, il est possible de faire payer le logiciel utilisant l’open source.
Depuis les débuts du mouvement pour les logiciels libres, les grandes entreprises technologiques sont passées du statut d’ennemis — Microsoft, Apple et IBM s’étant toutes opposées à l’open source à un moment donné — à celui de défenseurs de l’open source, Microsoft elle-même, ainsi que Google et Meta, se présentant comme de grands défenseurs. Cela reflète le fait qu’elles ont trouvé des moyens de contrôler la communauté open source et d’en tirer profit sans posséder les produits qui en résultent. Microsoft a racheté GitHub, une plateforme de développement logiciel de premier plan, pour 7,5 milliards de dollars en 2018. Cela a marqué un tournant dans le contrôle de Microsoft sur l’open source, lui permettant de récolter le code de tous les projets open source de GitHub et de constituer un ensemble de données de code pour former sa solution d’IA copilote.
Dans le même temps, Microsoft et d’autres grandes entreprises technologiques ont publié certaines de leurs solutions en open source. L’avantage est que le code open source est amélioré par des développeurs du monde entier, dont la plupart ne sont pas des employés. En 2018, sur GitHub, le vscode de Microsoft,[21] react-native de Facebook[22] et TensorFlow de Google figuraient parmi les projets open source les plus populaires en termes de nombre d’utilisateurs contribuant au code ; 59 %, 83 % et 41 % des contributeurs de chaque projet ne travaillaient pas pour Microsoft, Facebook et Google, respectivement. En 2023, vscode de Microsoft restait le premier projet open source en termes de nombre de contributeurs sur GitHub. Le classement des huit premiers projets en 2023 comprenait deux autres projets open source de Microsoft, dont l’un était axé sur les déploiements dans le cloud, et un kit de développement logiciel de Google pour la création d’applications appelé Flutter.[23]
Un autre avantage de l’open source réside dans les caractéristiques spécifiques de la communauté des développeurs de logiciels. Les développeurs et les ingénieurs sont, en général, de fervents partisans de l’open source. Les grandes entreprises technologiques veulent que les meilleurs développeurs et scientifiques travaillent pour elles, directement en tant qu’employés ou indirectement sous les formes décrites dans la section cinq. En permettant à leurs employés de contribuer à cette communauté, les Big Tech augmentent leur satisfaction et favorisent également les collaborations avec le monde universitaire ainsi qu’avec des scientifiques et des ingénieurs d’autres entreprises.
De plus, les Big Tech décident de ce qui est mis en open source afin d’étendre encore leur sphère de contrôle. Pour certaines d’entre elles, l’open source est devenu un élément essentiel de leur modèle économique. Cela leur permet de vendre des produits complémentaires ou, ce qui est encore plus rentable, de créer un écosystème autour de la solution open source. En contrôlant les compléments nécessaires, les Big Tech étendent leur contrôle et leurs profits sans acquérir de propriété supplémentaire.
L’exemple classique est celui d’Android, le système d’exploitation mobile de Google. Android est open source, ce qui a été déterminant pour son adoption massive par les fabricants de smartphones, au point qu’il est devenu le système d’exploitation utilisé dans tous les smartphones à l’exception des iPhones. L’open source, et le fait que Google ait négocié avec les fabricants pour préinstaller Google Play, la boutique d’applications Android, a incité les développeurs à coder des applications fonctionnant sous Android. Les développeurs d’applications prennent les risques économiques et liés à l’innovation, puis se retrouvent prisonniers de Google Play, payant une commission à Google pour chaque vente réalisée ou pour chaque publicité vendue si l’application est gratuite.
À long terme, le succès de l’open source est synonyme de normalisation. À mesure que leurs modèles deviennent des normes industrielles, les grandes entreprises technologiques renforcent leur leadership en utilisant l’open source pour signaler un consensus au sein de la communauté des développeurs. L’objectif est toujours de trouver des moyens de tirer profit non pas de la vente directe de la technologie mise en open source, mais de maximiser son utilisation et de l’exploiter ensuite pour générer des bénéfices.
Google a fait de sa bibliothèque logicielle pour l’apprentissage automatique, TensorFlow, une norme industrielle en la mettant en open source. Son utilisation s’est largement répandue, devenant presque une norme de codage, ce qui favorise les développements qui complètent parfaitement les produits Google. Il en va de même pour PyTorch, un framework d’apprentissage automatique mis en open source par Meta. Cette stratégie augmente le nombre de développeurs qui produisent des applications et d’autres produits complémentaires pouvant fonctionner sur les plateformes des Big Tech, dont leurs clouds sont un exemple frappant, car leurs frameworks de codage sont la norme. La définition des normes est également dynamique et, en introduisant de nouvelles solutions open source qui surpassent leurs logiciels initialement publiés, les Big Tech conservent leur avance. Dans d’autres cas, les Big Tech mettent à disposition des connaissances open source qui ne constituent pas le cœur de leurs avantages, notamment des modules que leurs concurrents potentiels pourraient également développer. L’open source est un moyen de les neutraliser.
Certains des LLM qui ont suivi ChaptGPT ont été mis en open source. Dans ce cas, l’open source signifie partager les paramètres du modèle, mais pas les données d’entraînement ni ce qui a conduit à inclure ou exclure certains paramètres, empêchant ainsi les concurrents de les imiter rapidement. Les exemples les plus marquants sont les modèles Llama, les LLM de Meta. Bien que l’open source ait initialement résulté d’une fuite accidentelle de la première version de Llama, il est rapidement devenu le modèle commercial de Meta.
Le PDG de Meta, Mark Zuckerberg, a expliqué les raisons qui ont motivé la décision de maintenir Llama en open source : cela signifie que les développeurs travaillent gratuitement sur Llama et fournissent des retours rapides. De plus, le modèle économique de Meta n’est pas de vendre l’utilisation de ses LLM, contrairement à OpenAI, et ne prend donc aucun risque en mettant son code en open source. En fait, en mettant Llama en open source, Meta favorise son adoption au détriment de ses concurrents, en particulier ChatGPT. Si Meta réussissait à faire de Llama la norme du secteur, cela signifierait que davantage de développeurs créeraient des solutions basées sur ce modèle. Les innovations de Meta seraient alors plus faciles à intégrer, ce qui pourrait créer un écosystème autour de Llama, à l’image de ce qu’a fait Google avec Android. Enfin, Zuckerberg a déclaré que l’open source de Llama permettait de satisfaire les employés et d’attirer davantage de talents chez Meta, à un moment où la réputation de Meta et la satisfaction de ses employés ont été compromises lors des licenciements massifs de 2023.
Ce que Zuckerberg n’a pas dit, c’est que Meta dépend d’autres grandes entreprises technologiques pour faire fonctionner Llama. Ne disposant pas de son propre cloud public, les LLM de Meta fonctionnent sur AWS, Google Cloud et Microsoft Azure. Bien que les modèles soient open source, leur accès implique des frais indirects liés à la location de la puissance de calcul. De plus, une clause cachée stipule que les entreprises comptant plus de 700 millions d’utilisateurs actifs doivent obtenir une licence distincte auprès de Meta. Cette clause vise à empêcher d’autres entreprises de développer une activité trop importante avec ces LLMs sans en informer Meta et sans lui verser de frais supplémentaires.
Dans le cas des LLMs de Meta comme dans celui d’OpenAI, nous voyons clairement le rôle central du cloud pour l’IA, depuis sa création jusqu’à son application. Il aurait été impossible pour OpenAI de former et d’exécuter ses modèles en interne ; cela aurait nécessité un nombre trop important de processeurs de pointe ultra-puissants et interconnectés, inaccessibles sans les Big Tech. La relation entre Microsoft et OpenAI illustre bien la manière dont les géants du cloud interagissent avec les petites entreprises qui développent des LLMs de pointe. Les start-ups et autres entreprises de taille moyenne spécialisées dans l’IA sont obligées de s’appuyer sur les clouds publics, car sans la puissance de traitement, les données et les connaissances techniques nécessaires pour configurer ces processeurs afin de former et d’exploiter les LLMs, l’IA ne pourrait pas fonctionner. Le fait que Microsoft propose également Llama sur son cloud alors que son accord avec OpenAI empêche cette dernière d’offrir le service ChatGPT sur d’autres clouds est une preuve supplémentaire des asymétries de pouvoir.
En bref, il est dans l’intérêt des géants de la technologie de mettre en open source les connaissances qu’ils contrôlent encore et de les intégrer à d’autres connaissances gardées secrètes. L’open source augmente également les taux de réussite et minimise les risques liés à l’innovation pour les géants de la technologie, qui continuent à transformer des modules de connaissances essentiels en actifs incorporels. En partie involontairement, même la communauté open source, qui a été encouragée pour contrebalancer le pouvoir des grandes entreprises technologiques, a été cooptée et le domaine de l’IA en général est désormais entre les mains des Big Tech. Toutes ces expériences ont en commun le fait que les Big Tech contrôlent sans posséder les technologies ni les autres organisations. En raison du rôle central de l’IA dans tous les domaines de la vie, il est urgent de réfléchir à des alternatives.
7 De la réglementation de l’IA contrôlée par les Big Tech à la production de l’IA dont la société et la planète ont besoin
Le choix n’est pas entre accepter la domination des Big Tech dans le développement de l’IA ou rejeter complètement l’utilisation de l’IA. Une alternative viable nécessite à la fois de réglementer les Big Tech et l’IA qu’elles promeuvent et, tout aussi important, de concevoir des institutions qui favorisent le développement d’une IA qui place les personnes avant les profits.
Depuis la sortie de ChatGPT, une grande partie du débat politique a porté sur l’autonomie des modèles d’IA de base, et même les dirigeants des grandes entreprises technologiques et d’OpenAI ont plaidé en faveur d’une réglementation des utilisations de l’IA. Cela détourne l’attention du public de la question de savoir quel type d’IA est codé, par qui et qui en tire profit. Réglementer la technologie ne signifie pas réglementer sa monopolisation, un aspect qui n’a toujours pas été abordé par les autorités antitrust.
Alors que le décret américain sur l’IA « Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence » se concentre uniquement sur les risques et les utilisations néfastes de l’IA, la loi européenne sur l’IA établit des obligations et des exigences de transparence pour les modèles d’IA à usage général. C’est là que les plus grandes difficultés sont imposées aux entreprises de Big Tech. Cela ne démantèle certes pas le contrôle des Big Tech sur l’ensemble de la chaîne de valeur de l’IA, mais au moins, cela les tient responsables de la manière dont leur technologie est utilisée. Cependant, les Big Tech et leurs satellites comme OpenAI auront plus de facilité à se conformer à ces réglementations, car ils disposent des ressources nécessaires, ce qui n’est pas nécessairement le cas des autres organisations travaillant sur les LLM ou d’autres modèles d’IA générative. De plus, la décision d’exclure les modèles open source de ce contrôle favorise directement Meta et profite indirectement à Microsoft, Amazon et Google, étant donné que Llama fonctionne sur leurs clouds.
Toutes les réglementations existantes manquent l’occasion d’exiger la publication des données d’entraînement des modèles de base, ainsi que des indicateurs, paramètres et variables utilisés pour les gérer. Les réglementations existantes ne couvrent pas non plus ce que des entreprises comme OpenAI font des données saisies comme invites pour interagir avec leurs LLMs. Et comme ces réglementations n’ont pas été accompagnées de réformes antitrust, elles ont manqué l’occasion de repérer et de réglementer l’utilisation du capital-risque des entreprises pour orienter et contrôler les start-ups spécialisées dans l’IA.
Dans ce contexte, où le scénario le plus probable est que l’IA restera contrôlée par quelques géants américains, il est urgent de proposer des alternatives publiques au développement de l’IA à des fins lucratives. Les sections suivantes proposent trois domaines dans lesquels il est possible d’explorer le développement de l’IA pour le bien public. L’IA n’est pas simplement la technologie de pointe de notre époque. Il s’agit d’une technologie à usage général, ce qui signifie qu’elle peut être largement appliquée à des utilisations très diverses. Et comme il s’agit d’une nouvelle méthode d’invention, elle a des répercussions directes sur la manière dont se déroulent les recherches scientifiques et technologiques.
L’IA pour relever les grands défis
L’IA est particulièrement utile pour traiter et synthétiser de grandes quantités d’informations, avec de multiples applications possibles pour relever les défis mondiaux.
Par exemple, l’IA pourrait être déployée dans la planification de la transition écologique, tant sur le plan stratégique que pour résoudre des goulets d’étranglement spécifiques. La gestion des énergies renouvelables est rendue plus efficace en centralisant les données sur l’offre et la demande et en les traitant à l’aide de l’IA. Les géants du cloud proposent déjà des services informatiques à cette fin tout en collectant des données sur l’énergie. L’État pourrait plutôt se poser en gestionnaire des sources de données énergétiques et utiliser l’IA pour mettre en place des réseaux intelligents publics visant à assurer une distribution de l’énergie plus efficace, moins coûteuse et plus équitable sur le plan social. La maintenance prédictive des forêts et, plus généralement, des parcs naturels, à l’aide de la vision par ordinateur et d’autres modèles d’IA, pourrait améliorer les prévisions en matière d’incendies de forêt et fournir des informations sur les espèces d’arbres les mieux adaptées au type de sol et de forêt. L’application de l’IA à ces fins et à d’autres fins sociales et environnementales[24] ne devrait pas se limiter aux solutions commerciales, notamment en raison du manque d’incitations privées à son adoption et de l’urgence de lutter contre la dégradation de l’environnement.
De nombreuses applications de l’IA pour l’environnement ne nécessitent pas de données à caractère personnel. Elles pourraient s’appuyer, par exemple, sur des données météorologiques qui sont ou pourraient être accessibles à des fins de recherche. Actuellement, les mêmes entreprises qui possèdent les plus grands ensembles de données à caractère personnel développent des modèles à partir de données publiques européennes. En novembre 2023, Google a publié un article dans la revue Science présentant les résultats de GraphCast, un modèle d’IA entraîné à partir des données météorologiques historiques du Centre européen pour les prévisions météorologiques à moyen terme (CEPMMT). Même si le modèle est mis en open source, les géants technologiques élargissent leurs connaissances en matière d’IA en entraînant des modèles à partir de données publiques. Le modèle obtenu peut être ajusté ou servir de base à d’autres modèles, puis vendu sous forme de service cloud. Aujourd’hui, des services informatiques pour les prévisions météorologiques sont déjà disponibles sur les clouds des Big Tech, et les données publiques de l’ECMWF et GraphCast pourraient être utilisées pour améliorer ces services.
Les données publiques ne devraient pas être partagées avec des entreprises qui collectent des données sur Internet pour ensuite les garder secrètes. La réciprocité devrait prévaloir. Si les entreprises technologiques veulent accéder aux données publiques, elles doivent être réciproques et partager leurs ensembles de données avec la communauté au sens large à des fins de recherche publique.
L’IA trouve également une autre application dans le domaine de la santé. Aujourd’hui, la numérisation des soins de santé est motivée par l’autocontrôle et l’autodiscipline, les appareils portables incitant les gens à prendre leur santé et leur bien-être en main. Au lieu de considérer les soins de santé comme une responsabilité sociale, ces appareils les individualisent davantage. Mais il existe d’autres utilisations alternatives de l’IA dans le domaine de la santé qui pourraient apporter des avantages sociaux plus importants. Des recherches ont montré que le programme mondial en matière de santé et de sciences biomédicales est dominé par les recherches sur le cancer et les maladies cardiovasculaires abordées sous l’angle de la biologie moléculaire. Les recherches sur les maladies négligées, les virus pathogènes, les bactéries ou autres micro-organismes et les vecteurs biologiques étaient marginales, du moins jusqu’en 2020, période couverte par cette étude.[25]
Si certaines de ces dernières ont évolué avec la pandémie, la recherche sur la prévention, les déterminants sociaux de la santé et l’évaluation des facteurs socio-environnementaux influençant l’apparition ou la progression des maladies reste négligée. L’approche qui domine, tant en termes de domaines privilégiés bénéficiant de financements privés et publics pour la recherche, est l’intervention thérapeutique et plus particulièrement pharmacologique à l’aide de médicaments. Il existe donc une marge de manœuvre importante pour évoluer vers une approche plus holistique. Au lieu de se concentrer sur les traitements et l’étude de la dégénérescence moléculaire, on pourrait envisager des recherches qui synthétisent de manière holistique plusieurs sources de données afin de prendre en compte les déterminants sociaux de la santé et d’évaluer les facteurs socio-environnementaux qui influencent l’apparition ou la progression des maladies. Cela nécessiterait une équipe interdisciplinaire, utilisant des méthodologies qualitatives complémentaires pour donner un sens aux résultats obtenus grâce à l’IA et accéder aux données de santé.
Solidarité des données
L’IA a besoin de données, et c’est l’un des avantages des géants de la technologie : ils accumulent depuis des décennies des données collectées librement auprès des citoyens et des organisations à grande échelle. Opposer cette collecte gratuite de données à la protection de la vie privée pourrait, dans une certaine mesure et si les entreprises respectent la réglementation, limiter leur gaspillage. Cependant, cela ne permettra pas de développer des alternatives à l’utilisation et au développement de technologies qui ne sont pas principalement motivées par le profit, mais qui sont avant tout bénéfiques pour les personnes, les autres êtres vivants et la nature.
Les bases de données publiques, telles que les ensembles de données sur les soins de santé, devraient être construites sur le principe de la solidarité des données. La notion de solidarité des données fait référence à la décision de partager les données et les informations entre les acteurs et les pays. Comme l’expliquent Kickbusch et Prainsack, dans le contexte de la pandémie de Covid-19, une fausse dichotomie s’est installée entre le respect de la vie privée et de la liberté des individus et la protection de la santé.[26] Cette dichotomie est fausse car les libertés individuelles nécessitent des biens collectifs, des biens communs qui permettent la réalisation de ces libertés individuelles, et vice versa.
Les données de santé anonymisées en sont un exemple. Sous réserve d’une réglementation et d’une gouvernance appropriées, leur accès pourrait non seulement contribuer à lutter contre les pandémies et autres crises mondiales, mais aussi à identifier des mesures visant à améliorer les conditions de vie de la population. Les données de santé traitées à l’aide de l’IA pourraient également fournir des éléments permettant d’améliorer la prévention, le diagnostic, le traitement et la prestation des soins. En bref, il est souhaitable de promouvoir la solidarité en matière de données, en particulier pour faire face à des situations critiques telles que les crises écologiques et sanitaires. Les coûts sociaux, notamment en termes de vies humaines, et les coûts environnementaux liés à la limitation de l’accès aux données pourraient être trop élevés.
La gouvernance des données à ces fins pourrait être confiée à l’Organisation mondiale de la santé. L’utilisation d’extraits de bases de données sur la santé devrait être garantie et facilitée à des fins de recherche, tout en préservant l’anonymat. Le rôle de l’OMS pourrait être de veiller à ce que les données ne soient partagées que lorsque leur analyse est associée à des enquêtes qui contribuent à accroître le bien public et dont les résultats restent dans la sphère publique. Un projet prometteur dans ce domaine pourrait être la centralisation des dossiers médicaux électroniques au niveau international ou en Europe. Ce projet nécessite l’intervention d’experts en informatique, en politique de santé publique, de chercheurs en sciences de la santé et biomédicales et de spécialistes en sciences sociales.
Au lieu de s’engager dans cette voie, le gouvernement britannique a de plus en plus ouvert l’accès aux données du NHS à de grandes entreprises technologiques, leur fournissant ainsi une ressource fondamentale pour faire progresser la marchandisation des soins de santé. Amazon avait conclu un accord avec le NHS pour fournir ses appareils Alexa aux hôpitaux, ce qui lui permettrait de collecter leurs données de santé. Fin 2023, le NHS a accordé à l’entreprise de surveillance technologique Palantir un contrat de 480 millions de livres sterling pour gérer sa plateforme de données. Il n’est donc pas surprenant que Google ait inclus le NHS dans sa liste de partenaires stratégiques pour les soins de santé en Europe, récemment créée, et qu’il développe un LLM adapté aux soins de santé tout en essayant de conclure un accord avec le NHS pour l’appliquer. Microsoft mène des recherches sur des applications similaires, à en juger par sa publication scientifique intitulée « Avantages, limites et risques du GPT-4 en tant que chatbot IA pour la médecine ».
Au-delà des soins de santé et des autres cas où les citoyens pourraient se voir offrir la possibilité de partager leurs données avec les États lorsque ces derniers leur fournissent un service, la solidarité des données doit également prévaloir dans les marchés publics. Les États devraient exiger des entreprises qui fournissent des services publics qu’elles partagent avec les municipalités et les conseils municipaux les données qu’elles collectent en tant que produit dérivé, qui doivent bien sûr être recueillies avec le consentement éclairé des personnes qui les produisent. Ces données pourraient contribuer à améliorer ces services. Par exemple, les données sur les itinéraires des vélos de location pourraient fournir des informations sur les endroits où il convient de donner la priorité à l’installation de pistes cyclables et où placer les stations de vélos.
Dans tous ces cas et dans d’autres utilisations potentiellement bénéfiques, la solidarité des données ne peut fonctionner que si les citoyens sont correctement informés des données qui seront collectées, des utilisations autorisées et du type d’utilisateurs de ces données. Cela nécessite des déclarations courtes et explicites qui informent les citoyens. L’application NHS, par exemple, pourrait inclure une fenêtre contextuelle demandant aux citoyens britanniques s’ils souhaitent partager leurs données, en précisant clairement quelles données seront partagées, leurs utilisations, qui y aura accès et en leur offrant la possibilité d’accéder aux résultats de la recherche. Ces fenêtres contextuelles doivent offrir des moyens faciles de se désinscrire, en interdisant les communications alambiquées telles que celles fréquemment utilisées pour nous dissuader de désactiver les cookies. Les données à caractère personnel ou les données susceptibles de donner lieu à des formes de surveillance et de contrôle ne devraient jamais être collectées (telles que les données relatives aux personnes qui louent des vélos publics).
Grandes collaborations pour une IA au service du bien commun
À l’heure actuelle, il est impossible d’envisager la production de modèles d’IA de base sans les géants de la technologie. Aucune institution ou organisation existante ne peut se permettre de produire des LLM ou d’autres modèles d’IA avancés sans s’appuyer sur les technologies contrôlées par Amazon, Microsoft ou Google, qui pourraient être étendues pour inclure les GPU IA de Nvidia, bien que les trois géants du cloud soient également en train de concevoir leurs propres semi-conducteurs IA. S’appuyer sur d’autres géants technologiques ne ferait pas beaucoup de différence en termes de subordination technologique, à l’exception du fait que les autres géants technologiques ne fourniront probablement pas les technologies de pointe, qui sont entre les mains des Big Tech américaines. Les États doivent mettre en place des alternatives indépendantes dans le but de développer l’IA pour le bien commun.
L’IA nécessite la collaboration d’un grand nombre de personnes. Le rapport de l’OpenAI présentant le GPT4 a été rédigé par 276 employés. Le rapport comprend une mention spéciale à Microsoft, car certains de ses employés ont également contribué au développement du GPT4, ainsi qu’aux testeurs adversaires et aux membres de l’équipe rouge (OpenAI, 2023).[27] Si plus de 300 personnes sont nécessaires pour développer un LLM, il est déraisonnable d’attendre d’une start-up ou d’une université qu’elle le fasse seule.
Le développement de modèles d’IA fondamentaux alternatifs ne sera pas financé par le capital-risque, qui est contrôlé par Amazon, Microsoft et Google et canalisé vers leurs propres priorités de recherche. Seul le financement public peut soutenir une IA transformatrice qui donne la priorité aux défis sociaux et environnementaux.
Une nouvelle institution publique de recherche chargée de soutenir le développement de modèles d’IA fondamentaux devrait idéalement être le fruit d’une collaboration internationale. Elle devrait développer des modèles pour le bien public, en tenant compte des impacts environnementaux, sociaux et culturels de l’IA, sans être soumise à l’impératif de rentabilité.
Cette institution devra ramener les talents issus des grandes entreprises technologiques. Cela nécessitera les cinq « P » :
- Un objectif ou une mission claire.
- Une puissance de traitement suffisante, qui pourrait également être largement utilisée pour d’autres projets de recherche publique.
- L’accès à des ensembles de données publiques, obtenu grâce à la solidarité en matière de données.
- Une rémunération adéquate (ce qui peut impliquer une augmentation générale des salaires dans le milieu universitaire).
- Des pairs, car l’IA fondamentale ne peut être produite de manière isolée ou en petits groupes avec un chercheur principal travaillant avec de jeunes chercheurs. Elle nécessite la collaboration de centaines de personnes expérimentées, de pairs.
8 Conclusion
Le degré de contrôle au-delà de la propriété de la chaîne de valeur de l’IA, de la recherche à l’adoption, justifie des mesures drastiques et urgentes. Les suggestions ci-dessus ne constituent qu’une première étape et doivent être débattues parallèlement à d’autres propositions dans des espaces démocratiques. Avant tout, les sociétés doivent discuter de manière démocratique et ouverte des types d’IA qui doivent être développés, par qui et à quelles fins. Cela est indissociable d’un accord sur le type de données qui seront collectées et sur la manière dont elles seront gérées (qui décidera des accès, comment elles seront accessibles, etc.). C’est maintenant qu’il faut façonner les technologies et redistribuer les gains qui y sont associés, car plus l’IA contrôlée par les géants technologiques sera utilisée et développée, plus il sera difficile de faire avancer une alternative. Et les formes actuelles d’IA, parce qu’elles privilégient le profit, finiront par remplacer la main-d’œuvre là où cela sera moins coûteux, seront utilisées pour contrôler les travailleurs qui conservent leur emploi sous la menace d’être remplacés, favoriseront les inégalités et déstabiliseront encore davantage la période critique que nous traversons.
Une dernière mise en garde concernant le risque du solutionnisme ou du déterminisme technologique. L’IA pourrait nous aider à relever les grands défis mondiaux, mais ni l’IA ni aucune autre technologie ne pourront résoudre ces problèmes à elles seules. Le type de vie que nous voulons mener est une décision politique ; la technologie peut, tout au plus, ouvrir la voie à un avenir meilleur. Sans contrôle démocratique de l’IA, cet avenir meilleur ne verra jamais le jour.
Methodological note
Figure 1: Network of main investors in the AI start-ups receiving funding since ChatGPT
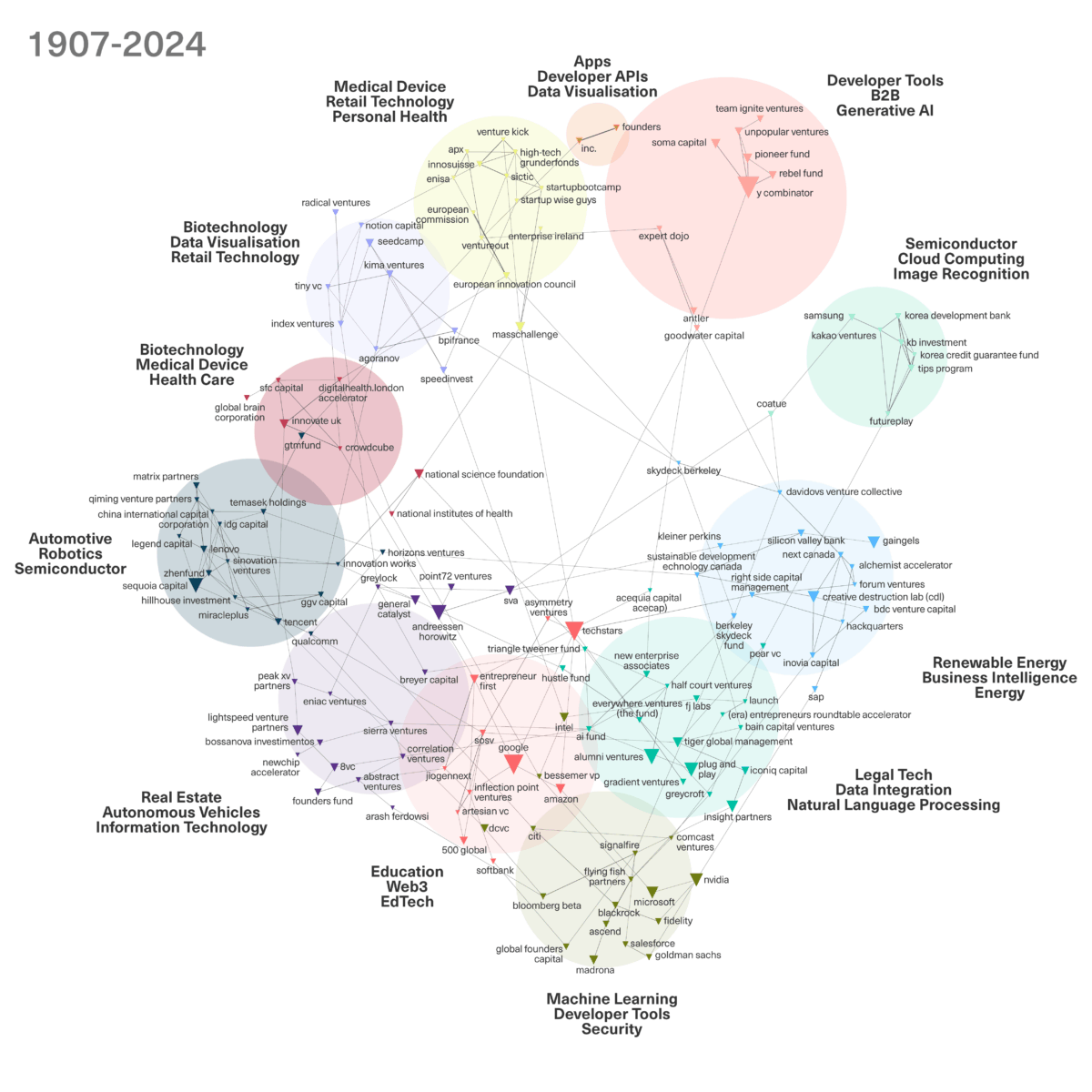
Pour la section trois, j’ai utilisé Crunchbase pour récupérer un ensemble de données contenant toutes les entreprises d’IA qui ont reçu un financement depuis le 30 novembre 2022, date de sortie de ChatGPT. Crunchbase est une base de données visant à fournir des informations commerciales sur les entreprises innovantes privées et cotées en bourse, en particulier les start-ups, aux sociétés de capital-risque.
Les données ont été traitées à l’aide de la plateforme CorText[28], qui nous a permis de construire des cartes de réseau à l’aide d’algorithmes spécifiques associant les entités en fonction de leur fréquence de cooccurrence dans un corpus.[29]Pour construire le réseau présenté dans ce rapport, l’algorithme de détection de communauté de Louvain a été appliqué comme méthode de détection de clusters.[30] Afin de me concentrer sur les investisseurs les plus influents, plutôt que de cartographier l’ensemble du réseau des principaux investisseurs des entreprises d’IA, j’ai donné la priorité aux 150 entités présentant la plus forte fréquence de cooccurrence. J’ai utilisé la mesure de proximité chi-carré pour déterminer les nœuds et les arêtes à prendre en compte dans la carte du réseau. Il s’agit d’une mesure locale directe, ce qui signifie qu’elle tient compte des occurrences réelles (investissements dans les mêmes entreprises d’IA) entre les entités. Pour définir les liens directs (arêtes), la normalisation chi-carré donne la priorité aux liens vers les nœuds de degré supérieur ; il s’agit des cooccurrences les plus fréquentes (financement des mêmes entreprises d’IA) au sein du réseau. Elle privilégie ainsi les liens les plus forts pour chaque organisation, de sorte que les arêtes peuvent être interprétées comme un indicateur de proximité entre les organisations.
Crunchbase fournit les domaines technologiques ou les secteurs d’activité (non distingués dans Crunchbase) dans lesquels chaque entreprise opère, selon une classification établie par Crunchbase et les entreprises elles-mêmes. J’ai répertorié la fréquence d’apparition de tous les domaines technologiques ou secteurs d’activité et j’ai représenté graphiquement les plus fréquents pour chaque cluster dans la figure 1.
J’ai également récupéré dans Crunchbase des informations sur le capital-risque des entreprises pour une sélection de géants technologiques au 24 février 2024. J’ai examiné toutes les entreprises qui comptaient l’un des géants technologiques de ma sélection parmi leurs cinq principaux investisseurs, puis j’ai filtré cette liste pour ne retenir que celles qui sont encore des entreprises privées et qui n’ont pas été retirées de la cote. Le tableau 1 présente le nombre d’entreprises les mieux financées pour chaque grande entreprise technologique.
Annexe : Le capital-risque des entreprises dans le secteur technologique
Si l’on considère non seulement les start-ups spécialisées dans l’IA, mais aussi l’ensemble de l’univers des start-ups, la pertinence du capital-risque des entreprises devient encore plus évidente (voir tableau 1). Cette pratique est particulièrement répandue chez Google, Intel et Microsoft, suivis par Alibaba, Samsung et Tencent. Le tableau 1 ne fournit que des données sur le nombre d’entreprises qui comptent une grande entreprise technologique parmi leurs cinq principaux investisseurs en février 2024, de sorte que les chiffres précis sont loin d’être définitifs. Toutefois, au-delà des chiffres, les grandes entreprises technologiques utilisent depuis des années le capital-risque comme moyen de contrôler les start-ups.
Table A1: Main Corporate VC Investments. Selected Firms.
| Corporation | Number of top investments | Share of US firms funded over total | Share of same country firms in total funding |
|---|---|---|---|
| 2445 | 44% | 44% | |
| Intel | 1028 | 66% | 66% |
| Microsoft | 823 | 27% | 27% |
| Tencent | 511 | 18% | 52% |
| Samsung | 390 | 47% | 21% |
| Alibaba | 330 | 6% | 66% |
| SAP | 280 | 59% | 11% |
| Amazon | 268 | 59% | 59% |
| Nvidia | 88 | 68% | 68% |
| Meta | 49 | 39% | 39% |
| Apple | 16 | 88% | 88% |
Source: Author’s analysis based on Crunchbase – data retrieved by late February 2024.
Bien qu’il existe de nombreuses preuves que le capital-risque d’entreprise soit une pratique courante chez la plupart des grandes entreprises technologiques, Apple fait figure d’exception notable. Loin d’être un signe de faiblesse, cela témoigne probablement de la nature de ses sphères de contrôle. Apple est une entreprise extrêmement hermétique qui entretient des relations avec d’autres organisations et tire profit de celles-ci en exigeant un niveau d’hermétisme similaire.
Notes
[1] “Annual Report 2023 — Form 10K”, Alphabet, 2024.
[2] Richard Phillips, Hannah Petersen and Ronen Palan, “Group subsidiaries, tax minimisation and offshore financial centres: Mapping organisational structures to establish the ‘in-betweener’ advantage”, Journal of International Business Policy, October 2020, vol. 4, pp. 286-307.
[3] Brian Callaci, “Control Without Responsibility: The Legal Creation of Franchising, 1960–1980”, Enterprise & Society, February 2020, vol. 22, pp. 156-182.
[4] Cédric Durand and William Milberg, “Intellectual monopoly in global value chains”, Review of International Political Economy, July 2018, vol. 27, pp. 404–429.
[5] Cédric Durand, Technoféodalisme: Critique de l’économie numérique, Zones: 2020; Ugo Pagano, “The crisis of intellectual monopoly capitalism”, Cambridge Journal of Economics, November 2014, vol. 38, pp. 1409–1429; Cecilia Rikap, Capitalism, Power and Innovation: Intellectual Monopoly Capitalism Uncovered, Routledge: 2020.
[6]Brett Christophers, Our Lives in Their Portfolios: Why Asset Managers Own the World, Verso Books: 2023; Nick Srnicek, “Value, rent and platform capitalism”, In Julieta Haidar and Maarten Keune (eds.), Work and Labour Relations in Global Platform Capitalism, Edward Elgar Publishing: 2021, pp. 29–45.
[7] Md Zahangir Alom et al., “The history began from alexnet: A comprehensive survey on deep learning approaches”, arXiv Preprint arXiv:1803.01164, 2018. Available here; Iain M. Cockburn et al., “The impact of artificial intelligence on innovation”, National Bureau of Economic Research, 2018. Available here.
[8] Multi-cloud, hybrid cloud and cloud agnostic solutions are being used. They are more expensive; thus, the cost savings of the cloud disappear, but these alternatives grant more bargaining power when negotiating cloud contracts.
[9] These data were scraped by Facundo Lastra.
[10] On AWS pricing see here and here.
[11] It is worth noting that BERD is considered in company-level accounting as an expenditure. This is why, unlike investments in plant and equipment, BERD is deducted for profit calculations. If we instead compute it as an investment and do not deduct it from the operating income of these companies, their profits would be even greater.
[12] Cecilia Rikap and Bengt-Åke Lundvall, The Digital Innovation Race Conceptualising the Emerging New World Order, Palgrave Macmillan: 2020.
[13] Michael Gofman and Zhao Jin, “Artificial Intelligence, Education, and Entrepreneurship”, Journal of Finance, Forthcoming, August 2022.
[14] Cecilia Rikap, “Same End by Different Means: Google, Amazon, Microsoft and Facebook’s Strategies to Dominate Artificial Intelligence”, CITYPERC Working Paper Series, 2023.
[15] Ibid.
[16] Ibid.
[17] Joel Klinger et al., “A narrowing of AI research?”, arXiv Preprint arXiv:2009.10385, 2020, p. 1. Available here.
[18] Rikap, “Same End by Different Means: Google, Amazon, Microsoft and Facebook’s Strategies to Dominate Artificial Intelligence”, CITYPERC Working Paper Series.
[19] Affiliations appear as Google, Google Research, Google Brain and DeepMind.
[20] Richard Stallman, Free software, free society: Selected essays of Richard M. Stallman, Lulu. Com: 2002; Sam Williams, Free as in freedom (2.0): Richard Stallman and the free software revolution, Free Software Foundation: 2010.
[21] Vscode is a source-code editor for modern web and cloud applications.
[22] React-native is a user interface software for app development.
[23] All this information was extracted from GitHub’s annual report which is called Octoverse and is available online. In the past, the report included more information, which is why it is not possible to update the figures that I have presented for 2018.
[24] A list of other potential uses can be found here.
[25] Federico E. Testoni et al., “Whose shoulders is health research standing on? Determining the key actors and contents of the prevailing biomedical research agenda”, PloS One, April 2021, vol. 16.
[26] Ilona Kickbusch and Barbara Prainsack, “Against data individualism: Why a pandemic accord needs to commit to data solidarity”, Global Policy, May 2023.
[27] OpenAI, “GPT-4 Technical Report”, arXiv Preprint arXiv:2303.08774, 2023. Available here.
[28] Elise Tancoigne, Marc Barbier, Jean-Phillippe Cointet, and Guy Richard, “The place of agricultural sciences in the literature on ecosystem services”, Ecosystem Services, December 2014, vol. 10, pp. 35–48.
[29] Marc Barbier, Marianne Bompart, Véronique Garandel-Batifol, and Andrei Mogoutov, “Textual analysis and scientometric mapping of the dynamic knowledge in and around the IFSA community”, in Ika Darnhofer, David Gibbon and Benoît Dedieu (eds.), Farming Systems Research into the 21st century: The new dynamic, Springer: 2012, pp. 73-94.
[30] Vincent D. Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre, “Fast unfolding of communities in large networks”, Journal of Statistical Mechanics: Theory and Experiment, April 2008.