
HENRY FARRELL. Original : https://www.programmablemutter.com/p/markets-bureaucracy-democracy-ai
L’un des grands trésors intellectuels du monde est le système Annual Reviews . Il publie des revues dans divers domaines des sciences et des sciences sociales, avec des articles qui ne visent pas à présenter les résultats de nouvelles recherches, mais à synthétiser ce qui se passe dans des domaines particuliers de la recherche et à proposer des pistes pour l’avenir. J’apprécie particulièrement l’Annual Review of Political Science, non seulement parce que je fais partie de son comité de rédaction, mais aussi parce que la plupart de son contenu est accessible gratuitement.
Le volume 2026, qui vient d’être publié, comprend un article que j’ai rédigé sur « L’IA comme gouvernance ». Il est disponible sous licence Creative Commons. Afin de faciliter sa réutilisation et son remixage, je fournis des versions Pandoc rudimentaires du texte en Word, Markdown et .tex. Si vous souhaitez simplement le lire, continuez à faire défiler la page ou cliquez ici et cliquez sur PDF dans le coin supérieur droit pour obtenir une version plus agréable à lire.
Si vous suivez cette newsletter depuis quelques années, vous y trouverez beaucoup d’éléments familiers. La seconde moitié de l’article, en particulier, est une version plus spécifique à la science politique de l’appliqué gopnikisme, tel que développé dans cet article de Science avec Alison Gopnik, Cosma Shalizi et James Evans, ainsi qu’ailleurs. Mais il y a quelques ajouts utiles au cadre organisationnel, notamment le tableau en haut de cet article, qui est délibérément épicé, au sens « quelque peu obscur et académique » du terme.
Nous reviendrons bientôt sur ce sujet, mais il est généralement plus utile de développer des idées et des cadres conceptuels dans le cadre d’une conversation que sous forme de grandes déclarations. Il y a notamment un débat très intéressant à mener avec Leif Weatherby dans son fascinant ouvrage tout récent, Language Machines. Mais ce livre mérite d’abord un article à part entière. En attendant, voici donc, à titre provisoire, « L’IA comme gouvernance ».
L’IA en tant que gouvernance
Cet ouvrage est sous licence Creative Commons Attribution 4.0 International, qui autorise une utilisation, une distribution et une reproduction sans restriction sur tout support, à condition que l’auteur original et la source soient mentionnés. Voir les mentions de crédit des images ou autres éléments tiers dans cet article pour plus d’informations sur la licence.
RÉSUMÉ
Les politologues se sont remarquablement peu exprimés sur l’intelligence artificielle (IA), peut-être parce qu’ils sont découragés par sa complexité technique et par les débats actuels sur la question de savoir si l’IA pourrait imiter, dépasser ou remplacer l’intelligence humaine individuelle. Ils devraient plutôt considérer l’IA en termes de relation avec la gouvernance. Les systèmes de gouvernance à grande échelle existants, tels que les marchés, la bureaucratie et la démocratie, rendent les relations humaines complexes plus faciles à gérer, même si cela s’accompagne d’une certaine perte d’information. Les principales conséquences politiques de l’IA peuvent être examinées sous deux angles. Premièrement, nous pouvons considérer l’IA comme une technologie de gouvernance et nous demander comment ses capacités à classer l’information à grande échelle affectent les marchés, la bureaucratie et la démocratie. Deuxièmement, nous pouvons considérer l’IA comme une forme émergente de gouvernance à part entière, dotée de ses propres mécanismes de représentation et de coordination. Ces deux perspectives soulèvent de nouvelles questions pour les politologues et les encouragent à reconsidérer les limites de leur discipline.
INTRODUCTION
Les politologues prennent tardivement conscience des débats publics sur l’intelligence artificielle (IA). L’apprentissage automatique (Grimmer et al. 2021, Morucci & Spirling 2024), rendu possible par de nouvelles techniques (réseaux neuronaux) et des équipements informatiques plus puissants, est en train de remodeler l’économie numérique, avec des conséquences possibles pour la société et la politique. L’IA générative, telle que les grands modèles linguistiques (LLM) et les modèles de diffusion, a suscité un énorme enthousiasme – et inquiétude – car ses résultats peuvent se rapprocher de contenus générés par l’homme, tels que des textes, des images et, de plus en plus, des vidéos.
Si certains politologues étudient les conséquences politiques secondaires de l’IA, rares sont ceux qui s’intéressent à son fonctionnement spécifique, qui semble relever du domaine des informaticiens. Le terme « IA » suggère que ces technologies doivent être comparées à l’intelligence humaine individuelle, que certains s’attendent à voir l’IA imiter ou surpasser, plutôt qu’à des phénomènes politiques ou sociaux collectifs.
Les sciences sociales ont plus à apporter qu’elles ne le pensent (Oduro & Kneese 2024). Des débats animés sur la politique des algorithmes et des données (Burrell & Fourcade 2021, Johns 2021, Matias 2023) qui examinent comment les LLM peuvent constituer une « technologie culturelle » (Yiu et al. 2024) qui résume, organise et remixe les connaissances produites par l’homme sont déjà en cours. Les politologues peuvent utilement réfléchir à l’IA en termes de relation avec les dispositifs de gouvernance, les divers moyens collectifs à grande échelle par lesquels les humains traitent l’information et prennent des décisions, tels que les marchés, la bureaucratie et la démocratie. Les dispositifs de gouvernance ne pensent pas (Arkoudas 2023, Mitchell 2023, Nezhurina et al. 2024), mais ils réorganisent utilement les connaissances et les activités humaines. Il en va de même pour l’IA (Yiu et al. 2024).
Outre la question de savoir comment l’IA doit être gouvernée (Stanger et al. 2024), nous pouvons considérer l’IA comme une technologie de gouvernance. L’IA fournit de nouveaux moyens pour mettre en œuvre les tâches fondamentales (telles que la classification ou la catégorisation) sur lesquelles reposent les marchés, la bureaucratie et la démocratie. Certains types d’IA, tels que les LLM, pourraient devenir suffisamment distincts et importants pour constituer une forme de gouvernance à part entière, un moyen collectif indépendant de traitement et de coordination de l’information, équivalent aux marchés, à la bureaucratie et à la démocratie, plutôt qu’un simple complément technologique.
Dans la pratique, l’IA se confond avec le comportement du marché, la routine bureaucratique et (peut-être à l’avenir) la représentation démocratique, tout comme, par exemple, les marchés se fondent dans la bureaucratie intra-entreprise. Mais considérer l’IA comme une technologie ou une forme de gouvernance aide les spécialistes des sciences sociales à comprendre comment étudier l’IA et à aborder des questions actuellement obscurcies par un discours enthousiaste sur l’intelligence surhumaine imminente.
L’étude de la gouvernance et de l’IA exigerait des politologues qu’ils acquièrent une certaine compréhension technique de l’IA et qu’ils réfléchissent plus clairement à la relation entre la politique et la technologie. Il y a un demi-siècle, Simon [2019 (1968)] suggérait de considérer les sciences sociales et l’IA comme des manifestations des « sciences de l’artificiel ». Nous devrions prendre cette suggestion au sérieux. Tout comme les grandes sciences sociales ont été une réponse au choc de la révolution industrielle (Tilly 1984), nous devrions travailler de manière interdisciplinaire, voire créer de nouvelles disciplines, pour répondre aux changements moins importants mais potentiellement impressionnants qui se produisent actuellement autour de nous.
CE QUE SIGNIFIENT L’IA ET LA GOUVERNANCE
L’IA et la gouvernance sont des termes controversés. John McCarthy a inventé le terme « intelligence artificielle » pour le distinguer de la cybernétique (Mitchell 2019), qui s’intéressait aux flux de rétroaction et d’informations dans une grande variété de systèmes (Davies 2024). Cependant, la signification de l’IA a évolué. Pendant des décennies, l’IA a été dominée par des approches symboliques, qui mettaient l’accent sur la logique et les règles dérivées de manière formelle. Aujourd’hui, l’approche connexioniste rivale, qui combine l’apprentissage automatique et les réseaux neuronaux (moteurs de traitement statistique qui ressemblent en théorie à des réseaux de neurones biologiques), est en plein essor (Mitchell 2019). Toutes les IA soi-disant ne font pas appel à ces techniques, et l’IA n’est pas le meilleur terme pour les décrire, mais c’est celui qui s’est imposé.
L’IA connexioniste analyse les données afin de découvrir des représentations approximatives utiles pour des relations qui peuvent être obscures, complexes et non linéaires. Les réseaux neuronaux sont des modèles multicouches qui créent, modifient et transmettent des hypothèses pondérées sur divers aspects des données via des « couches cachées » de « neurones ». Le résultat final est repondéré via une descente de gradient (ou rétropropagation) afin de mieux converger vers un optimum global.
Ces modèles peuvent classer et prédire. Dans l’apprentissage supervisé, l’IA est entraînée sur des données étiquetées, généralement sur des images qui ont été étiquetées comme contenant des chats ou des chiens. Au fur et à mesure que les données des images passent par les couches du réseau neuronal, le modèle peut identifier des caractéristiques de plus en plus complexes (par exemple, des motifs associés à une forme particulière d’oreille) qui sont plus susceptibles d’être trouvées dans des images étiquetées « chat » que « chien ». Il peut également relever des informations non saillantes : par exemple, si les chats sont plus susceptibles d’être photographiés à l’intérieur et les chiens à l’extérieur, il peut supposer à tort que les chiens photographiés à l’intérieur sont des chats. Dans les modèles d’apprentissage non supervisé tels que les LLM (Radford et al. 2019), l’IA est chargée de prédire ou de classer à partir de modèles non étiquetés dans les données.
Certaines applications de l’IA (par exemple, la modélisation du repliement des protéines) sont éloignées des sciences politiques. D’autres pourraient directement remodeler l’économie, la société et la politique. Les systèmes d’IA sont évolutifs, même si leur formation et leur mise en œuvre peuvent être coûteuses en termes de calcul, et les processus par lesquels ils parviennent à des résultats spécifiques peuvent être opaques. Il est souvent impossible de déterminer comment un réseau neuronal traite les données initiales pour parvenir à sa décision finale de classification, et les techniques utilisées pour améliorer la descente de gradient sont basées sur des essais et des erreurs « alchimiques » (Rahimi & Recht 2017) plutôt que sur une compréhension approfondie.
Les LLM tels que GPT-4.5 sont produits par des transformateurs, une architecture de réseau neuronal qui encode les relations entre les mots vectorisés et les parties de mots (tokens) dans d’énormes corpus de texte extraits d’Internet, de livres numérisés et d’autres contenus facilement accessibles. Le transformateur produit un ensemble de vecteurs pondérés qui capturent sa cartographie des relations entre les tokens de mots dans le corpus (qu’il s’agisse de mots apparaissant régulièrement ou rarement à proximité les uns des autres). Cet ensemble de vecteurs constitue le LLM qui, après un traitement supplémentaire (ajustement technique et apprentissage par renforcement grâce au retour d’information humain ou, de plus en plus, à des données synthétiques), peut prédire le texte ou le contenu qui devrait suivre une invite donnée.
Les politologues pourraient s’intéresser à l’IA en étudiant sa relation avec la gouvernance. Comment l’IA affecte-t-elle les formes existantes de gouvernance, telles que les marchés, la hiérarchie bureaucratique et la démocratie ? L’IA est-elle elle-même une forme de gouvernance ?
Cependant, la gouvernance est également un terme controversé (Mayntz 2009). Comme le remarque avec ironie Peters (2012, p. 19), « l’ambiguïté du concept […] a été l’une des raisons de sa popularité. […] Il […] obscurcit le sens tout en améliorant peut-être la compréhension.» Peters note toutefois que malgré la diversité de ses significations, le mot « gouvernance » désignait à l’origine le fait de diriger un bateau, comme la cybernétique (dérivé du mot grec attique signifiant « art de diriger »). La gouvernance, tout comme la cybernétique et le contrôle (Beniger 1986, Wiener 2019, Yates 1993), est un terme générique qui désigne les formes de coordination sociale, politique et économique qui mettent particulièrement l’accent sur le traitement de l’information.
En m’inspirant largement des idées analogues présentées par Simon [2019 (1968)], je considère la gouvernance comme un terme générique désignant les systèmes à grande échelle de traitement de l’information et de coordination sociale qui permettent aux sociétés complexes de fonctionner. Un système de gouvernance comprend donc (a) une entrée, une source à grande échelle d’informations complexes ; (b) une technologie permettant de transformer ces informations en représentations utiles, bien que sujettes à des pertes, qui peuvent être plus facilement manipulées ; et (c) des sorties qui peuvent être utilisées pour coordonner sur la base de ces représentations.
Sur les marchés, le mécanisme des prix résume les connaissances tacites (Polanyi 1966) sur les relations de production, permettant une coordination économique à grande échelle (Hayek 1945, Lindblom 2002). Dans la hiérarchie bureaucratique, les relations d’autorité et les systèmes de classification transforment les connaissances sociales diffuses en informations exploitables qui permettent au gouvernement d’élaborer des règles (Scott 1998, Weber 1968). Dans la démocratie, les mécanismes de représentation et d’expression transforment les désirs et les connaissances des citoyens en représentations exploitables qui permettent un retour d’information et un contrôle sur leur situation collective (Allen 2023, Dewey 1927).
Ces systèmes de gouvernance sont, au mieux, très imparfaits. Le mécanisme des prix, les catégories bureaucratiques et les représentations du public démocratique sont des « simulations » [Simon 2019 (1968)] ou des approximations très approximatives (Flack 2017) de réalités sous-jacentes irréductiblement complexes. Mais même les critiques les plus sévères (Scott 1998) reconnaissent que les sociétés modernes à grande échelle seraient impossibles sans elles.
Ils sont profondément imbriqués les uns dans les autres. Les marchés dépendent à la fois des institutions gouvernementales externes (North 1990) et de la hiérarchie bureaucratique interne des entreprises (Coase 1937). Les bureaucraties s’appuient sur les marchés et ont régulièrement cherché à en importer la logique (Dunleavy & Hood 1994). La démocratie dépend de la hiérarchie bureaucratique pour mettre en œuvre les décisions et, comme l’observe Lindblom (2002), semble pratiquement indissociable de l’économie de marché.
La valeur de cette approche de la gouvernance ne réside pas dans le fait qu’elle fournit des définitions précises, et encore moins des hypothèses vérifiables, mais plutôt dans le fait qu’elle offre une heuristique large. Nous pouvons voir comment l’IA peut ne pas être un substitut présumé à l’intelligence humaine individuelle, mais plutôt un moyen de traitement et de coordination collectifs de l’information. Plus précisément, nous pouvons considérer l’IA soit (a) comme une technologie externe, qui influence la manière dont les systèmes de gouvernance existants coordonnent et traitent l’information, soit (b) comme une forme de gouvernance à part entière, avec sa propre forme particulière de coordination et de traitement de l’information. Comment l’IA affecte-t-elle le fonctionnement interne des formes de gouvernance existantes ? Pourrait-elle devenir une forme de gouvernance à part entière, avec ses propres pièges et possibilités (Farrell & Shalizi 2023) ? Ces deux grandes questions motivent des programmes de recherche différents mais convergents (concurrents ? – overlapping).
L’IA EN TANT QUE TECHNOLOGIE DE GOUVERNANCE
Comment l’IA a-t-elle affecté les formes de gouvernance existantes telles que les marchés, la bureaucratie et la démocratie ? Les politologues pourraient s’inspirer des travaux de chercheurs en sciences et technologies (Beniger 1986, Yates 1993), en communication (Noble 2018), en sociologie (Fourcade & Johns 2020) et en histoire (Cronon 1991), qui ont examiné la succession des technologies ayant influencé le fonctionnement des bureaucraties, des marchés et peut-être même de la démocratie.
Les marchés, la bureaucratie et la démocratie impliquent tous une classification, et l’IA fournit des systèmes de classification à grande échelle. Bowker & Star (2000, p. 11) définissent un système de classification comme un « ensemble de boîtes (métaphoriques ou littérales) dans lesquelles on peut mettre des choses pour ensuite effectuer un certain type de travail, qu’il soit bureaucratique ou de production de connaissances ». Non seulement les bureaucraties, mais aussi les marchés et les démocraties s’appuient sur des systèmes de classification, par exemple pour permettre le commerce impersonnel (Cronon 1991) et pour rendre tangibles les besoins et les souhaits des publics démocratiques (Perrin & McFarland 2011). Aujourd’hui, l’IA peut attribuer automatiquement et à grande échelle des personnes, des choses et des situations à des cases. YouTube, par exemple, peut utiliser l’IA pour classer des milliards d’utilisateurs particuliers, en devinant quelle vidéo proposer à chacun. En fonction de la réponse de l’utilisateur, l’algorithme peut mettre à jour sa classification sans intervention humaine.
Que se passe-t-il donc lorsque les anciens systèmes de classification (allant de technologies aussi prosaïques que les classeurs à de vastes entreprises collectives telles que les recensements) sont modifiés ou remplacés par l’IA (Farrell & Fourcade 2023) ? Les conséquences immédiates sont particulièrement visibles sur les plateformes en ligne telles que YouTube et Facebook. L’IA génère des catégories très fines ; par exemple, le système de recommandation de YouTube décrit ci-dessus a déployé des intégrations (représentations de relations) à haute dimension des vidéos et des utilisateurs afin de générer et de classer une liste de vidéos candidates à proposer ensuite (Covington et al. 2016). Ces catégorisations peuvent changer rapidement et sans préavis : personne n’y a directement accès sans disposer d’un accès interne à la technologie.
Ces techniques sont appliquées à grande échelle par les entreprises de plateformes, mais de manière aléatoire ailleurs. L’adoption de l’IA serait assez lente. McElheran et al. (2024) constatent que seulement 6 % des entreprises américaines, représentant environ 18 % de l’emploi total, déclarent utiliser l’IA (bien que la plupart des très grandes entreprises y aient recours). Aux États-Unis, de nombreuses agences fédérales ont expérimenté la « réglementation artificiellement intelligente » (Engstrom et al. 2020), mais les changements ont été très lents (Cuéllar & Huq 2022). Les recherches existantes sur l’adoption de l’IA par les gouvernements en Chine, en Inde, en Europe et ailleurs suggèrent un tableau similaire : beaucoup d’intérêt, mais un déploiement lent. Si les discussions sur la démocratie améliorée par l’IA abondent (Allen & Weyl 2024, Gilman & Cerveny 2023, Landemore 2021, Sanders et al. 2024), il n’existe aucune mise en œuvre réelle à grande échelle.
Il est possible que l’IA n’ait pas les conséquences économiques, organisationnelles et politiques à grande échelle que beaucoup attendent. Ses avantages pourraient être limités ou compensés par d’autres desiderata, elle pourrait s’avérer présenter des défauts irrémédiables ou susciter une opposition politique insurmontable. Cependant, les nouvelles technologies sociales ont très rarement un impact immédiat et spectaculaire, en particulier lorsque leur utilisation nécessite des changements organisationnels à grande échelle.
Il est sage d’envisager au moins la possibilité que l’IA ait également des conséquences à grande échelle, même si celles-ci ne se manifestent qu’après des années, voire des décennies. Si, comme le suggèrent Cuéllar & Huq (2022, p. 335), une nouvelle « ère » de réglementation (et de marchés et de politique) artificiellement intelligente est à nos portes, nous devrions commencer à réfléchir à ses implications. Cela doit nécessairement relever de la spéculation, en extrapolant à partir de ce que nous pouvons observer (par exemple, la mise en œuvre des plateformes) et de déductions raisonnables sur les développements futurs.
D’un certain point de vue, l’économie des plateformes semble démontrer comment l’IA peut dynamiser la coordination des marchés. Des plateformes telles que Facebook et YouTube utilisent d’autres algorithmes que l’IA et ont été créées avant que l’IA connexioniste ne se développe, mais elles s’appuient de plus en plus sur l’IA pour automatiser les boucles de rétroaction dans lesquelles les utilisateurs, les contenus ou les situations sont classés et traités, puis les conséquences sont mesurées et réinjectées dans le système (Fourcade & Healy 2024). Les plateformes ont parié qu’une grande partie de la coûteuse hiérarchie bureaucratique interne de l’entreprise pouvait être remplacée par des fonctions objectives qui orientent les technologies d’IA vers la maximisation ou la minimisation d’un ensemble de vecteurs (Reich et al. 2021). Cela aide les entreprises de plateformes qui emploient des dizaines de milliers de personnes à gérer les interactions entre des centaines de millions, voire des milliards d’utilisateurs. Les décisions plus sensibles sont toujours prises par des humains, tandis que des contractuels mal payés assurent la modération algorithmique et sont obligés de se confronter quotidiennement à certains des aspects les plus toxiques du comportement collectif humain (Gonzalez & Matias 2024).
L’IA peut sous-tendre les marchés d’attention bilatéraux, dans lesquels les plateformes publient des contenus créés par les consommateurs tandis que les annonceurs se disputent l’attention des consommateurs. Elle facilite également le fonctionnement de vastes marchés traditionnels, tels qu’Amazon, eBay et Temu, avec peu de contrôle humain. Nous en savons plus sur les premiers que sur les seconds, en partie en raison de problèmes de disponibilité des données [qui suscitent à la fois une mobilisation des chercheurs (Coalit. Indep. Technol. Res. 2024) et des réponses politiques (Eur. Comm. 2024)].
Les économistes et de nombreux informaticiens se sont concentrés sur l’efficacité des algorithmes d’IA. Des sociologues, des spécialistes de la communication et d’autres informaticiens plus pessimistes se sont interrogés sur leur incidence sur la responsabilité et les relations de pouvoir au sein des bureaucraties publiques et privées, soulignant souvent le manque de rigueur, les biais et l’imperméabilité de l’IA aux corrections extérieures.
Les erreurs de prédiction et de catégorisation sont inévitables. Les algorithmes d’IA sont des moyens imparfaits pour ajuster des courbes à des processus complexes qu’ils cherchent à résumer. Les propriétaires de plateformes se soucient souvent avant tout d’exploiter les économies d’échelle et sont relativement insensibles aux erreurs locales. Amazon utilise l’IA pour embaucher et licencier ses chauffeurs indépendants, sur la base de décisions de classification qui peuvent sembler arbitraires pour les humains. Comme l’a expliqué en termes vulgaires à Bloomberg (Soper 2021) l’un des ingénieurs qui a conçu le système : « Les dirigeants savaient que ça allait merder. C’est d’ailleurs ainsi qu’ils l’ont formulé lors des réunions. La seule question était de savoir combien de merde nous voulions qu’il y ait. » Plus généralement, les ingénieurs se considèrent souvent comme faisant partie d’un « nous » qui conçoit et met en œuvre les systèmes plutôt que comme faisant partie du « eux » que ces systèmes sont censés catégoriser, gérer et prédire (Eliassi-Rad 2024).
L’IA peut également refléter ou accentuer les préjugés. L’apprentissage de l’IA peut détecter des préjugés sexistes, raciaux ou autres dans les données sur lesquelles il a été formé. Dans un cas très médiatisé (Dastin 2018), Amazon aurait formé un système à partir des CV de candidats retenus pour trier les nouvelles candidatures. Le système d’apprentissage pénalisait les CV qui contenaient le mot « femmes », comme dans « capitaine du club d’échecs féminin », transformant ainsi des préjugés informels passés en critères de sélection directs. Ces préjugés peuvent potentiellement s’autoalimenter, y compris dans des fonctions gouvernementales très sensibles. Benjamin (2019)soutient que les décisions policières algorithmiques peuvent transformer les préjugés en rétroaction, par exemple en identifiant les zones où le nombre d’arrestations est élevé (probablement en raison de préjugés raciaux) afin d’y renforcer l’intervention policière, ce qui peut à nouveau augmenter le nombre d’arrestations dans une boucle de rétroaction perverse. Si certains criminologues (par exemple, Berk 2021) affirment que ces préoccupations sont exagérées, ils reconnaissent toutefois que les préoccupations légitimes en matière d’équité et d’exactitude sont fondées.
Il peut exister des formes plus subtiles de préjugés. Les catégories sous-représentées dans les données d’apprentissage seront mal prises en compte par le modèle. En outre, il existe des compromis fondamentaux entre différents types de préjugés (Chouldechova 2017, Kleinberg et al. 2018) qu’il est impossible de résoudre complètement. Ces problèmes et d’autres problèmes connexes sont abordés dans une littérature très vaste qui a des implications politiques importantes, mais qui a jusqu’à présent été développée principalement par des informaticiens et des philosophes, plutôt que par des politologues et des théoriciens politiques.
L’adoption généralisée de l’IA par les entreprises de plateformes et la perspective de son utilisation à plus grande échelle suscitent de vifs débats sur la meilleure façon de corriger les biais et les erreurs, en particulier lorsque les gouvernements s’en emparent. Certains spécialistes des sciences sociales sont pessimistes : Fourcade & Gordon (2020) suggèrent que « l’État dataiste » réduit progressivement le pouvoir discrétionnaire des bureaucrates et crée des boîtes noires algorithmiques. D’autres sont prudemment optimistes, arguant que les algorithmes peuvent parfois être plus responsables que les bureaucrates (Kleinberg et al. 2018) ou que, avec des garanties appropriées, l’IA peut offrir une plus grande efficacité avec des inconvénients acceptables.
Les optimistes se concentrent souvent sur les fonctions objectives que l’IA et d’autres algorithmes maximisent ou minimisent : celles-ci décrivent les objectifs et les compromis de manière plus transparente que, par exemple, les directives bureaucratiques traditionnelles. Les pessimistes soulignent la difficulté de retracer et de comprendre comment les algorithmes d’apprentissage de l’IA prennent des décisions particulières. Il est souvent impossible de suivre les facteurs qui alimentent une décision spécifique qui passe par plusieurs couches cachées dans un réseau neuronal, et de toute façon, ces facteurs pourraient ne pas se traduire facilement en notions humaines traditionnelles de responsabilité et d’éthique bureaucratique.
Ces perplexités suggèrent que certains commentaires populaires et semi-populaires sur le « capitalisme de surveillance » tout-puissant (Zuboff 2019) et sa convergence avec l’autoritarisme (Harari 2018) sont exagérés. Les partisans comme les détracteurs ont tendance à surestimer l’efficacité de l’IA (Healy 2016). E. Yang (manuscrit non publié) constate que les techniques de surveillance par IA de la Chine sont mal adaptées pour prédire les troubles politiques pour le régime sans données provenant d’autres sources. Ce qu’il veut savoir, c’est précisément ce qu’il ne peut pas observer facilement, car les citoyens s’autocensurent, faussant ainsi les données d’entraînement. L’IA peut aider les autoritaires à passer au crible de vastes quantités de données ; elle peut également renforcer leurs préjugés politiques internes et les rendre moins aptes à voir ce qui est pertinent pour leur survie. Ces sujets font l’objet de beaucoup moins de recherches que leur importance ne le justifie.
Plus généralement, il existe remarquablement peu de recherches comparant systématiquement la prise de décision bureaucratique traditionnelle et le recours aux algorithmes d’IA. Les bureaucraties traditionnelles sont des fondements essentiels des sociétés complexes, mais elles sont parfois monstrueuses, comme le décrit Kafka (Jarrell 1941), ayant permis le massacre des Juifs, des Roms, des Sintis et d’autres populations en Europe par les nazis et contribué à précipiter la grande famine en Chine, ainsi que d’autres crimes et catastrophes à grande échelle (Scott 1998).
Une partie du problème est d’ordre traductionnel : si les politologues réfléchissent et écrivent beaucoup sur la bureaucratie et ses conséquences, ils utilisent des cadres informationnels différents de ceux des informaticiens. Un regain d’intérêt pour la bureaucratie en tant que système de traitement de l’information contribuerait à jeter des ponts (D. Berliner, manuscrit non publié). Il existe néanmoins quelques recherches pertinentes. Alkhatib & Bernstein (2019, p. 2) observent que les algorithmes, y compris les algorithmes d’IA, peuvent être moins bien adaptés que les bureaucrates de terrain pour remodeler des catégories à la volée, notant que lorsque les algorithmes « rencontrent un cas nouveau ou marginal, ils exécutent leur limite de classification pré-entraînée, potentiellement avec une confiance erronée élevée » (voir également Kaminski & Urban 2021). Des recherches beaucoup plus approfondies sont nécessaires dans ce domaine.
Les questions politiques soulevées par le feedback vont au-delà de la bureaucratie. Certains chercheurs suggèrent que les boucles de feedback de l’IA pourraient renforcer la démocratie, en permettant une meilleure mesure des opinions, en améliorant le feedback des personnes moins aptes à articuler et à défendre leurs intérêts en termes technocratiques, ou en fournissant aux citoyens un feedback qui interroge leurs points de vue et les guide vers une compréhension commune du bien. D’autres craignent que l’IA ne sape les formes existantes de coordination démocratique et de création de connaissances. Ils suggèrent que l’IA pourrait potentiellement aggraver la polarisation en facilitant les boucles de rétroaction des réseaux sociaux qui optimisent l’engagement (en proposant aux utilisateurs des contenus politiques provocateurs qui les incitent à rester connectés mais les radicalisent) ou en inondant le débat politique d’un tel déluge d’absurdités que toute discussion normale devient impossible, aggravant ainsi les préoccupations existantes concernant les réseaux sociaux (Pomerantsev 2014, Roberts 2018). Ces pronostics très différents ont suscité des discussions animées sur la question de savoir si la consommation de désinformation ou de mésinformation (deux termes controversés) et la polarisation accrue sont davantage le fait de la technologie ou d’une demande préexistante de certains citoyens (Budak et al. 2024, Munger 2024).
Si les politologues ont participé à ces débats, ils ont souvent intégré l’IA dans des controverses existantes plutôt que d’examiner si elle pouvait en générer de nouvelles. Les affirmations selon lesquelles l’IA peut être utilisée pour reconstruire la démocratie sur des bases plus solides ont généralement associé des descriptions épistémiques de la démocratie (Schwartzberg 2015) à l’enthousiasme des ingénieurs pour l’optimisation. Ces approches ont tendance à négliger la discussion sur les compromis entre les différents types d’informations que les citoyens pourraient apporter et les besoins réels du processus politique (D. Berliner, manuscrit non publié). Elles surévaluent également les aspects de la démocratie liés à la production de connaissances et sous-estiment la lutte politique entre différentes approches de la politique et de la vie (Schwartzberg 2015). Une grande partie de la littérature émergente préfère ignorer les aspects controversés de la politique démocratique, suggérant qu’ils pourraient être modérés ou contournés grâce à la combinaison de l’apprentissage automatique et de la délibération citoyenne.
Il existe un vaste champ de recherche et de réflexion sur la manière dont l’IA intersecte les controverses politiques, sur ses conséquences pour les groupes et les partis organisés, et sur la manière dont elle pourrait affecter la répartition politique du pouvoir. Ces algorithmes réduisent-ils la diversité au sein des organisations (Caplan & boyd 2018), ou remodèlent-ils la conception collective de ce qui constitue le public démocratique ? Pourraient-ils même constituer de nouveaux types de citoyens (Fourcade & Healy 2024), réorganisant leur relation avec la politique pour mettre l’accent sur le classement « ordinal » (Nguyen 2021) et la compétition individualisée ? Ces questions sont à la fois très peu étudiées par les politologues et d’une importance capitale pour leurs intérêts.
De même, alors que les politologues ont débattu avec enthousiasme des conséquences potentiellement négatives des algorithmes des réseaux sociaux, ils ont accordé peu d’attention à la manière dont les plateformes sont organisées et modérées (Steinsson 2024). Cela a laissé le champ libre aux chercheurs en information, communication, science et technologie, qui ont débattu de la politique de modération (Gillespie 2018, Matias 2019a), des publics en réseau (Bak-Coleman et al. 2021, boyd 2010, York & Zuckerman 2019, Zuckerman 2014), le pouvoir (Lazar 2024) et le harcèlement en ligne (Matias 2019b). Ces chercheurs sont en désaccord sur de nombreuses questions importantes, mais ils s’accordent à dire que la gestion par les entreprises de plateformes des interactions entre des centaines de millions ou des milliards d’utilisateurs n’est pas seulement technique, mais intrinsèquement politique. Les entreprises de plateformes ont cherché à échapper à ces considérations politiques (Gillespie 2018) en invoquant, avec plus ou moins de cynisme, la rhétorique de la liberté d’expression et du marché de l’information ; en suggérant, de manière peu plausible, que des solutions à grande échelle émergeront naturellement des utilisateurs eux-mêmes ; en atténuant les désaccords politiques ; ou en se tournant vers des sources de légitimité extérieures pour traiter les questions politiques épineuses. Aucune de ces stratégies n’a fonctionné. Nous devons de toute urgence accorder beaucoup plus d’attention à la manière dont les entreprises ont déployé l’IA pour organiser ces espaces et à la manière dont les utilisateurs ont réagi, d’autant plus que les propriétaires de plateformes tels qu’Elon Musk (X) et Mark Zuckerberg (Meta) se montrent de plus en plus disposés à prendre parti en politique.
Plus largement, les politologues doivent réfléchir plus profondément à la manière dont les technologies de gouvernance affectent la coordination démocratique et le traitement de l’information. La politique démocratique dépend également des technologies de classification, même si les politologues les explorent rarement (voir toutefois Prior 2007). Comme l’ont souligné les sociologues politiques (Perrin & McFarland 2011), la notion vague de « public démocratique » est concrétisée par des technologies sociales telles que les sondages d’opinion, auxquels les politiciens et d’autres acteurs ont recours pour se faire une idée générale de ce que pense le « public » et des catégories particulières auxquelles appartiennent les citoyens. Ces sondages peuvent activement façonner et constituer des publics démocratiques, créant ainsi des prophéties auto-réalisatrices (Rothschild & Malhotra 2014). Il en va de même pour d’autres technologies, notamment les systèmes de vote. Quels types d’individus, de collectivités et de publics démocratiques l’IA peut-elle donc faire émerger ? Comment l’IA pourrait-elle remodeler notre compréhension du public à l’avenir ? S’il existe un débat organisé sur ce sujet, ce n’est pas parmi les politologues.
Comprendre comment l’IA peut agir comme une technologie de gouvernance, influençant la manière dont les marchés, la bureaucratie et les démocraties coordonnent leurs actions, donnera lieu à de nombreux programmes de recherche importants. Cela devrait également inciter les politologues à prêter une attention particulière aux angles morts de leur propre compréhension collective de la politique. En tant que discipline, nous ne réfléchissons pas régulièrement à la manière dont la technologie affecte les structures profondes de l’économie politique, le gouvernement dans les régimes démocratiques et autocratiques, ainsi que la représentation démocratique et le retour d’information. Cela doit changer.
L’IA COMME FORME DE GOUVERNANCE
Considérer l’IA comme une technologie de gouvernance est déjà un défi pour les sciences politiques. Mais on pourrait aller plus loin. L’IA pourrait-elle devenir une forme nouvelle et distincte de traitement de l’information et de coordination sociale, plutôt qu’une technologie secondaire qui affecte les modes existants ? En d’autres termes, est-il logique de considérer certaines formes d’IA comme une forme émergente de gouvernance à part entière ? Cela permettrait d’élaborer un programme sur la base des idées communes présentées par Farrell et al. (2025).
Les grands modèles – les LLM et les formes connexes d’IA générative – ont des implications qui semblent aller au-delà de leurs conséquences immédiates pour les marchés, la bureaucratie et la démocratie. Plus précisément, ils rendent certains types d’activités culturelles plus faciles à gérer qu’auparavant, ce qui affecte les possibilités de coordination culturelle autour de croyances communes et ouvre de nouvelles possibilités pour amplifier ou contrer les préjugés et pour la découverte ou la reproduction.
Il existe une justification possible pour considérer les grands modèles comme une nouvelle forme de gouvernance. Comme le soutient Simon [2019 (1968)], les êtres humains (a) ont une capacité individuelle limitée de traitement de l’information et (b) vivent dans un monde extrêmement complexe. Par conséquent, les humains s’appuient sur diverses technologies externes pour coordonner le traitement de l’information et réduire la complexité à des simplifications gérables.
Dans cette perspective, les marchés, la bureaucratie et la démocratie génèrent tous des représentations imparfaites mais utiles qui rendent plus faciles à gérer des réalités sociales sous-jacentes d’une complexité impossible. Les prix résument les connaissances tacites incarnées dans les relations économiques de production, contribuant ainsi à la coordination du marché ; les catégories bureaucratiques résument les connaissances sociales diffuses, permettant la coordination gouvernementale ; et les représentations démocratiques du public résument les convictions et les aspirations politiques des citoyens, permettant la coordination politique. Toutes représentent indifféremment les réalités complexes sous-jacentes qu’elles prétendent comprendre, mais toutes sont essentielles à la gestion des complexités de la société moderne. Nous ne pouvons faire des choix concernant notre destin collectif qu’à travers les représentations imparfaites qui le rendent visible.
Comme nous le verrons ci-dessous, les grands modèles fournissent également des résumés imparfaits mais utilisables de corpus de connaissances beaucoup plus vastes, rendant ainsi plus maniables des ensembles sous-jacents d’une complexité impossible à appréhender. Ils créent des représentations utiles mais imparfaites de grandes catégories de connaissances culturelles (Yiu et al. 2024), extraites d’Internet et d’autres sources. Les grands modèles sont et génèrent des représentations de la culture écrite et des images, résumant d’énormes corpus d’informations extraits d’Internet, de sources numérisées et d’autres sources.
Comme c’est le cas, par exemple, pour les prix et les catégories bureaucratiques, ces représentations sont manipulables (Farrell et al. 2025), contrairement aux ensembles qu’elles représentent. Plus précisément, ces modèles peuvent être interrogés pour révéler des relations qui ne sont pas immédiatement visibles, pour combiner différents aspects de la culture qu’ils représentent de manière apparemment créative, et pour étendre, réduire et transformer des productions culturelles discrètes.
Ces opérations formelles n’ont rien de magique : elles sont (dans leur forme actuelle) des applications pratiques de techniques de prédiction statistique à des corps de texte vectorisés. Dans un exemple canonique tiré d’un ancêtre des LLM, word2vec, en soustrayant le vecteur « homme » du vecteur « roi » et en ajoutant le vecteur « femme », on obtient approximativement le vecteur « reine ». Lorsqu’on demande à un LLM, par exemple, de réécrire l’intrigue de Hamlet dans le style d’un manuel de chimie, il utilise des opérations similaires, bien que plus complexes, sur des résumés vectorisés pour interpoler l’intrigue et le style et fournir une réponse probable quant à ce à quoi pourrait ressembler la combinaison. Cette technologie présente des défauts. La tendance des LLM à « halluciner », c’est-à-dire à générer des résumés plausibles mais incorrects, fait partie de leur fonctionnement. Plus généralement, comme l’affirment Yiu et al. (2024, p. 875), les LLM sont incapables de distinguer « les représentations véridiques des représentations non véridiques », car ils n’ont aucune interaction directe avec le monde matériel et ne sont pas capables d’apprendre directement de celui-ci. Ce qu’ils font en réalité, c’est modéliser le contenu culturel généré par l’homme de manière maniable et manipulable.
Cela reste tout à fait extraordinaire. Nous disposons désormais de technologies qui peuvent faire pour la culture écrite et visuelle quelque chose de similaire à ce que les prix font pour les informations économiques et les catégories bureaucratiques pour les informations sociales. Les grands modèles génèrent des représentations d’un tout vaste et insaisissable qui ne capturent pas entièrement ce tout, mais qui sont manipulables et reproductibles à grande échelle. Début 2025, des entreprises et des sociétés connexes telles qu’OpenAI misent des centaines de milliards de dollars sur l’hypothèse que cette technologie deviendra une véritable technologie à usage général, remodelant la manière dont les êtres humains accèdent à la culture écrite, visuelle et audiovisuelle, la remixent et la créent. Si ce pari risqué s’avère payant, les grands modèles deviendront une technologie intermédiaire cruciale pour la reproduction de la culture humaine, façonnant les croyances communes, renforçant ou atténuant les préjugés, influençant les processus de découverte et remodelant les relations politico-économiques sous-jacentes. Cela justifierait de considérer les grands modèles comme une forme alternative de gouvernance qui peut en principe être comparée aux marchés, à la bureaucratie et à la démocratie (tableau 1).
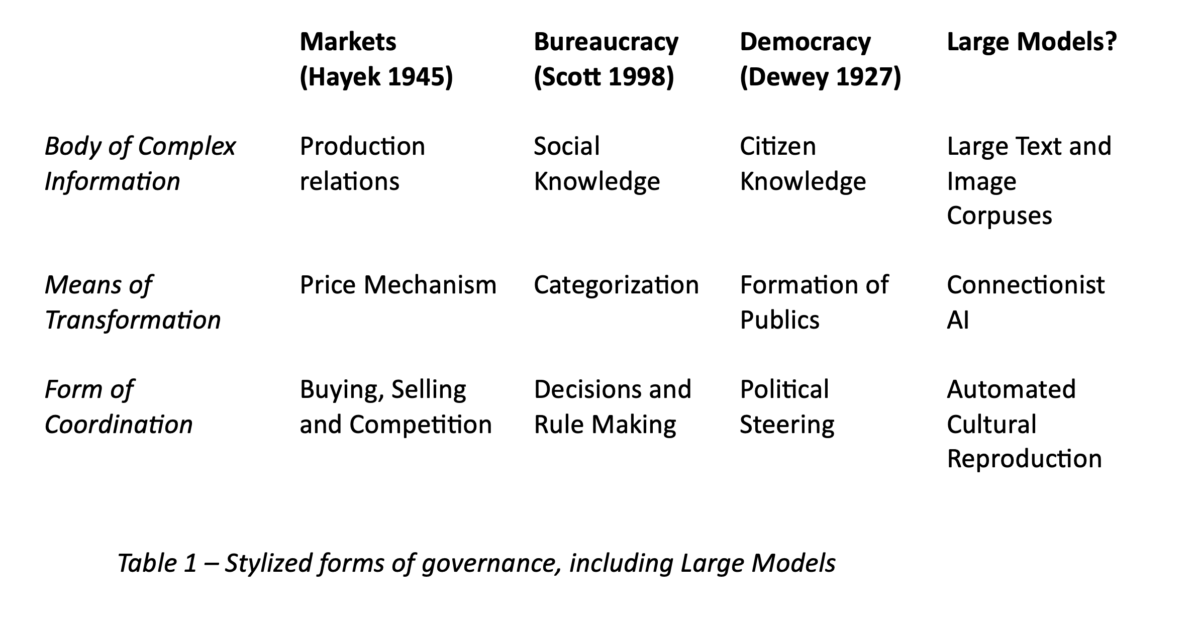
Comme pour la création des marchés impersonnels (Cronon 1991) et de l’État bureaucratique (Yates 1993), les conséquences probables seraient des bouleversements politiques, sociaux et économiques. De nouvelles formes de traitement de l’information apparaîtront dans le domaine culturel, et d’anciens problèmes réapparaîtront sous de nouvelles formes.
Les premiers systèmes automatisés de génération de contenu culturel étaient assez limités. Les moteurs conversationnels (Weizenbaum 1966) et les outils algorithmiques (Eno 1976), combinatoires (Queneau 1961) et aléatoires (Calvino 2012) de génération culturelle ont généralement stimulé la créativité et l’expression humaines plutôt que de les remplacer. Aujourd’hui, nous disposons d’algorithmes prédictifs qui ne nécessitent qu’une intervention humaine minimale pour générer des réponses fluides et détaillées, souvent difficiles à distinguer de celles d’un être humain. Nos architectures cognitives nous prédisposent à considérer certains schémas d’activité comme le produit d’agents conscients et volontaires, ce qui nous conduit, par exemple, à confondre de nombreux phénomènes naturels avec des dieux (Atran 2004). Les LLM ne sont ni conscients ni dotés d’une volonté propre, mais ils donnent l’impression de l’être, et leurs résultats peuvent être aussi convaincants que ceux d’une conversation humaine.
Les conséquences de la persuasion automatisée font l’objet d’un débat animé. Dans un article très lu, Bender et al. (2021, p. 617) décrivent les grands modèles comme des « perroquets stochastiques » et s’inquiètent du fait que « la fluidité et la cohérence artificielles [des grands modèles] soulèvent plusieurs risques, précisément parce que les humains sont prêts à interpréter les chaînes appartenant à des langues qu’ils parlent comme ayant un sens et correspondant à l’intention communicative d’un individu ou d’un groupe d’individus responsables de ce qui est dit ».
Ces préoccupations ont alimenté les inquiétudes existantes concernant la désinformation politique en ligne, faisant craindre que les LLM automatisent la production de propagande hautement persuasive (Goldstein et al. 2024, Kreps & Kriner 2024). D’autres ont fait valoir que le pouvoir de persuasion des LLM pourrait être politiquement bénéfique, dans la mesure où le dialogue avec les LLM pourrait réduire la croyance des gens dans les théories du complot (Costello et al. 2024) ou produire des déclarations consensuelles suscitant une plus grande adhésion parmi des personnes ayant des opinions politiques divergentes (Tessler et al. 2024). Aucune de ces deux écoles de pensée n’a encore établi de liens systématiques avec la littérature en sciences politiques sur la persuasion (Coppock 2023) ni exploité de manière exhaustive la littérature psychologique sur la communication, la tromperie et la vigilance (Sperber et al. 2010). S’il y a des raisons de soupçonner que les craintes concernant la désinformation alimentée par l’IA sont « exagérées » (Simon et al. 2023), la propension des grands modèles à générer des réponses sans surprise aux requêtes initiales pourrait cibler les angles morts de l’architecture cognitive humaine (Sobieszek & Price 2022). L’évaluation des conséquences plus larges n’en est qu’à ses débuts. Nous en savons beaucoup moins que nécessaire sur l’interaction entre la cognition humaine et les résultats des LLM.
Les conflits de longue date sur le contrôle culturel s’étendent à de nouveaux domaines, à mesure que les biais de l’IA se confondent avec les biais culturels (Gallegos et al. 2024). Les LLM et les modèles connexes sont entraînés à partir d’une grande variété de contenus culturels, dont une grande partie est récupérée sur Internet. Le résultat prévisible est qu’ils « encodent des associations stéréotypées et péjoratives liées au genre, à la race, à l’origine ethnique et au handicap » (Bender et al. 2021, p. 613). Les LLMs sont moins visiblement biaisés qu’auparavant, en partie grâce à l’apprentissage par renforcement, mais ils reviennent souvent, par exemple, à des stéréotypes de genre dans les images qu’ils génèrent, ou attribuent des noms typiquement noirs à des personnages stéréotypés dans les scénarios générés. L’apprentissage par renforcement a ses limites. Comme le décrit Resnik (2024, p. 3), « pour parler franchement… beaucoup de ce qui se trouve dans la tête des gens est nul… et, surtout… les LLM n’ont aucun moyen de distinguer ce qui est nul de ce qui ne l’est pas ».
Une solution apparemment simple pourrait être de cesser de former les grands modèles sur des contenus culturels biaisés. Cependant, ceux-ci sont nécessairement volumineux : ils nécessitent d’énormes corpus de contenus culturels. Les entreprises et les entités nominalement ou réellement à but non lucratif qui développent des LLM sont généralement peu enclines à faire preuve de sélectivité dans la collecte de textes et d’images. En outre, elles sont moins disposées qu’auparavant à divulguer leurs sources (Dodge et al. 2021), car elles cherchent à préserver leurs secrets commerciaux, à contourner les restrictions (Longpre et al. 2024) et à repousser les demandes d’indemnisation de ceux qui ont généré les contenus culturels sur lesquels les modèles sont entraînés.
De manière plus générale, les solutions techniques sont peu adaptées pour résoudre le problème des biais. Cela s’explique en partie par les limites technologiques (Wolf et al. 2023). Comme le soulignent Bommasani et al. (2021, p. 134), « les mesures techniques actuelles, quelles qu’elles soient, sont très limitées : les méthodes qui mesurent ou combattent les biais intrinsèques sont fragiles ou inefficaces…Les méthodes qui mesurent ou combattent les disparités extrinsèques dans les résultats peuvent ne pas correspondre aux objectifs des parties prenantes […] et certaines données suggèrent que certains types d’interventions techniques peuvent être à la fois insatisfaisants […], impossibles […] ou même exacerber les inégalités ». Les solutions techniques qui résolvent certains problèmes peuvent finir par en aggraver d’autres.
Cependant, les dilemmes les plus profonds sont d’ordre politique et non technique. Il n’existe pas de consensus général sur ce qu’est le biais, quels biais sont problématiques et comment ou si les biais doivent être supprimés. Au contraire, il existe un désaccord politique profond. Cela est en partie inévitable, compte tenu des enjeux, mais il est exacerbé par un décalage général entre les débats prétendument techniques sur les biais de l’IA et les discussions en sciences sociales et en théorie politique sur le fonctionnement de la dissidence, quand elle est inévitable, quand elle peut être atténuée et quand elle présente des avantages. Ce décalage contribue à une compréhension superficielle de ce qu’implique le biais et de ses conséquences possibles (Blodgett et al. 2020). Il rend également plus difficile la discussion des désaccords politiques fondamentaux. Les LLM doivent-ils corriger une « vision dominante/hégémonique » (Bender et al. 2021) qui renforce les formes existantes d’inégalité et d’oppression ? Devraient-ils plutôt refléter une version non filtrée du contenu culturel qui leur a été fourni, au motif que cela reflète une version élargie du « marché des idées » (Zhang 2024) ? Il s’agit là de questions profondément politiques, même si peu de politologues ou de théoriciens se sont penchés sur la question jusqu’à présent.
Une autre série de débats porte sur la manière dont les LLM peuvent affecter la découverte et la créativité humaines, dans la mesure où ils influencent la création de contenu culturel. La description concise des LLM par Chiang (2023) comme des « JPEG flous » de l’Internet suggère que leur principale conséquence sera de dégrader la créativité et la découverte humaines, en les remplaçant par un ensemble imprécis et intrinsèquement non créatif d’approximations et d’interpolations. D’autres (Shumailov et al. 2024 ; voir également Alemohammad et al. 2023, Marchi et al. 2024) affirment que les LLMs sont soumis à la « malédiction de la récursivité ». Comme ils génèrent une part de plus en plus importante du contenu culturel, ils sont susceptibles d’être de plus en plus alimentés par leurs propres productions. Cela conduira à une forme dégénérative d’« effondrement du modèle », dans laquelle les erreurs s’accumulent et s’autoalimentent, finissant par produire des absurdités incohérentes. De même, une certaine quantité de données synthétiques générées par les LLM peut être utile : la détermination des conditions pratiques de l’effondrement récursif est un sujet de recherche ouvert. Fourcade & Farrell (2024) avancent un argument similaire mais moins convaincant, s’appuyant sur la sociologie plutôt que sur l’informatique, pour suggérer que les LLM sont extrêmement bien adaptés à l’exécution automatisée de rituels organisationnels, tels que la production de déclarations personnelles et d’évaluations de performances. À mesure qu’ils se multiplient, les obligations sociales génératrices d’informations, telles que l’évaluation par les pairs dans le milieu universitaire, pourraient se dégrader, entraînant une baisse du niveau des connaissances et de la confiance (Z. Wojtowicz & S. DeDeo, manuscrit non publié).
D’autres chercheurs affirment le contraire, arguant que les LLM et les technologies connexes peuvent favoriser la créativité et la découverte plutôt que de les compromettre. De manière évidente, les LLM peuvent automatiser des tâches fastidieuses, telles que la synthèse de longs textes et la génération de bibliographies (ils le font de manière imparfaite, mais c’est également le cas des assistants de recherche). Cependant, ils peuvent également permettre des découvertes plus larges. Les intégrations au cœur de ces modèles peuvent fournir des indices synthétiques sur les modèles culturels et sociaux dans lesquels s’inscrivent les découvertes. Cela explique pourquoi le biais des LLM est un problème si difficile à résoudre, mais fournit également des moyens plus sophistiqués pour cartographier la culture ( Kozlowski et al. 2019). La combinaison de word2vec et d’un réseau neuronal convolutif permet de cartographier de très grands corpus de textes scientifiques, en identifiant des combinaisons possibles de concepts et de matériaux qui ne viendraient pas spontanément à l’esprit des êtres humains, mais qui pourraient aboutir à des découvertes novatrices (Sourati & Evans 2023). Plus généralement, la combinaison de l’étude de l’IA générative et des modèles évolutifs pourrait fournir des informations utiles sur la manière dont les LLM influencent la conservation sélective de certains aspects de la culture, ainsi que la production de variations dans d’autres (Brinkmann et al. 2023, Yiu et al. 2024). La littérature sur la résolution de problèmes complexes soutient que ces problèmes sont plus facilement résolus lorsque des agents ayant des compréhensions diverses de l’espace problématique peuvent combiner leurs représentations (Bednar & Page 2018, Hong & Page 2004). Certaines recherches préliminaires suggèrent que les modèles génératifs peuvent imiter de manière approximative le vote majoritaire au sein d’un groupe de personnes ayant une compréhension moins sophistiquée du problème, en éliminant les erreurs idiosyncrasiques (Zhang et al. 2024). Il reste à découvrir si ces modèles, qui contiennent certainement des informations compressées sur les divers points de vue de nombreux acteurs, peuvent être déployés de manière plus véritablement créative.
Enfin, les grands modèles génèrent des batailles politiques pour savoir qui obtient quoi dans l’économie de la production culturelle. Comme indiqué ci-dessus, des questions restent en suspens (Ramani & Wang 2023) quant à savoir si et comment l’IA conduira aux vastes transformations économiques prédites par les optimistes. Mais elle conduira certainement à des formes moins radicales de disruption, alors que les producteurs culturels se disputeront la répartition des bénéfices et des coûts. Ce que les grands modèles font de manière la plus évidente, c’est de générer des substituts imparfaits à de nombreux produits du travail culturel humain : codes logiciels, articles, livres, images et, de plus en plus, contenus vidéo. Ces substituts pourraient concurrencer la production humaine originale sur le marché, générant des tensions économiques qui pourraient ressembler aux bouleversements du début du XIXe siècle, lorsque les formes artisanales ont été remplacées par la production industrielle de masse, provoquant la formation du mouvement luddite (Acemoglu & Johnson 2023, Thompson 1963).
On ne sait pas encore dans quelle mesure l’IA générative pourra remplacer le travail créatif humain. À ce jour, il n’existe pratiquement aucune preuve de déplacement de main-d’œuvre (Acemoglu et al. 2022). Les résultats des grands modèles présentent encore un degré assez élevé d’imprécision et d’incohérence et ont souvent tendance à être génériques, ce qui limite leurs applications à un certain nombre de tâches à forte valeur ajoutée. Cela pourrait changer.
Si ces problèmes ne sont pas résolus, l’IA générative sera moins largement applicable et le potentiel de controverse politique autour de ses utilisations sera d’autant plus faible. Mais dans la mesure où l’IA s’avère utile, elle est susceptible de remplacer le travail de travailleurs relativement hautement qualifiés, qui sont vraisemblablement mieux placés pour défendre leurs intérêts que les travailleurs non qualifiés et semi-qualifiés des pays industrialisés avancés, qui ont perdu leur pouvoir de négociation au cours des dernières décennies. Les recherches existantes et à venir (par exemple, Thelen 2025) permettent de mieux comprendre les conséquences économiques de l’économie des plateformes, mais il existe encore très peu de travaux des politologues sur les conséquences politico-économiques des algorithmes et de l’IA en tant que tels.
Comme pour d’autres formes d’IA, l’importance à long terme des grands modèles reste incertaine. Néanmoins, leur comparaison avec les formes de gouvernance à grande échelle existantes permet de mettre en évidence leurs similitudes de principe et fournit des représentations utiles, mais imparfaites, de vastes corpus de connaissances culturelles. S’ils s’imposent et se généralisent, ces modèles sont susceptibles de remodeler les processus de reproduction et de coordination culturelles.
CONCLUSIONS
Tilly (1984) déplorait que les sciences sociales croulent encore sous le poids de la révolution industrielle et de la réorganisation de la société et de l’économie qu’elle a entraînée. Il souhaitait savoir « comment nous pouvons améliorer notre compréhension des structures et des processus à grande échelle qui ont transformé notre monde au XIXe siècle et qui le transforment encore aujourd’hui » (p. 2).
Quarante ans plus tard, nous sommes confrontés à une nouvelle version du défi lancé par Tilly, alors que les technologies remodèlent l’économie de manière imprévisible mais potentiellement lourde de conséquences. Ces changements sont probablement moins importants que les conséquences de l’industrialisation du XIXe siècle, ils sont davantage des répliques que le séisme lui-même (Shalizi 2010). Mais ils n’en restent pas moins importants.
Cette analyse suggère que nous pouvons relever ce défi en reconsidérant la relation entre l’IA et les types de « structures et processus à grande échelle » dont parlait Tilly. En considérant l’IA comme une technologie de gouvernance, nous pouvons nous demander comment elle modifie les marchés, les processus bureaucratiques et les formes de représentation démocratique qui ont remodelé le monde pendant la révolution industrielle. En supposant, à l’inverse, qu’elle pourrait devenir une forme de gouvernance, nous pouvons nous demander si elle pourrait avoir des conséquences transformatrices en soi.
De tels arguments sont nécessairement provisoires et spéculatifs. J’ai souligné que la gouvernance et l’IA sont des concepts vagues qui sont plus utiles comme heuristiques que comme générateurs d’hypothèses. Mais une spéculation structurée peut avoir une valeur à un moment où des changements à grande échelle et imprévisibles se produisent. Il est certes possible que l’IA n’ait pas de conséquences à grande échelle sur la politique et la société, mais il est pour le moins raisonnable de se demander si elle pourrait en avoir et, dans l’affirmative, quelles pourraient être ces conséquences. En examinant à la fois comment elle pourrait affecter l’ancien et comment elle pourrait ouvrir la voie à du nouveau, nous pouvons commencer à organiser nos recherches.
Il y a énormément de questions à se poser. Comme le suggère cette analyse, les questions de recherche ouvertes sont bien plus nombreuses que les réponses. Il existe toute une série de questions que cet article n’a pas eu la place d’aborder correctement, voire de mentionner dans certains cas, par exemple les conséquences de l’IA sur la stabilité autoritaire, sur la politique internationale (Horowitz & Lin-Greenberg 2022) et sur le développement économique, ainsi que le débat sur le calcul socialiste. Et il existe certainement d’autres sujets méritant notre attention qui sont occultés par les angles morts intellectuels de cette revue, mais qui pourraient apparaître – et s’avérer urgents – sous d’autres angles.
Toutes ces questions constituent des défis pour les politologues, qui ont pris du retard par rapport aux informaticiens, sociologues, économistes, spécialistes de la communication, chercheurs en sciences et technologies, et autres dans l’étude de l’IA. Pour rattraper leur retard, ils devront acquérir de nouvelles compétences et une meilleure compréhension des technologies.
À plus long terme, ces derniers, ainsi que d’autres spécialistes des sciences sociales, des informaticiens et des ingénieurs, devront peut-être redéfinir les frontières disciplinaires afin de mieux refléter les changements politiques, économiques, sociaux et technologiques. Lorsque Simon [2019 (1968)] soulignait que les sciences sociales et l’étude de l’IA pouvaient facilement être regroupées sous le terme de « sciences de l’artificiel », il exprimait une version particulière d’une ambition plus générale. Depuis des décennies, divers cybernéticiens, chercheurs en IA, scientifiques de la complexité et autres souhaitent regrouper les différents systèmes par lesquels les humains traitent l’information collective et prennent des décisions dans un cadre analytique commun.
Cette ambition a été régulièrement exprimée, et tout aussi régulièrement contrariée. Elle continuera probablement à l’être dans un avenir prévisible. Mais à mesure que les chercheurs de différentes disciplines commenceront à repousser les limites de leur discipline pour y intégrer de nouvelles questions, ils modifieront inévitablement la perception qu’ils ont de leur discipline. Ils pourraient trouver de manière inattendue des points communs avec des chercheurs issus de domaines très différents. Les anciennes disciplines changeront de position et de nouvelles pourraient émerger. Si les politologues veulent prendre part à ce débat (et ils devraient le vouloir), ils doivent se dépêcher.
Références
- Acemoglu D, Autor D, Hazell J, Restrepo P. 2022.. Artificial intelligence and jobs: evidence from online vacancies. . J. Labor Econ. 40:(Suppl. 1):S293–340 [Crossref] [Google Scholar]
- Acemoglu D, Johnson S. 2023.. Power and Progress: Our Thousand-Year Struggle over Technology and Prosperity. New York:: Hachette[Google Scholar]
- Alemohammad S, Casco-Rodriguez J, Luzi L, Humayun AI, Babaei H, et al. 2023.. Self-consuming generative models go MAD. . arXiv:2307.01850 [cs.LG]
- Alkhatib A, Bernstein M. 2019.. Street-level algorithms: a theory at the gaps between policy and decisions. . In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pap . 530. New York:: ACM [Google Scholar]
- Allen D. 2023.. Justice by Means of Democracy. Chicago:: Univ. Chicago Press [Google Scholar]
- Allen D, Weyl EG. 2024.. The real dangers of generative AI. . J. Democr. 35:(1):147–62 [Crossref][Google Scholar]
- Arkoudas K. 2023.. GPT-4 can’t reason. . arXiv:2308.03762 [cs.CL]
- Atran S. 2004.. In Gods We Trust: The Evolutionary Landscape of Religion. Oxford, UK:: Oxford Univ. Press [Google Scholar]
- Bak-Coleman JB, Alfano M, Barfuss W, BergstromCT, Centeno MA, et al. 2021.. Stewardship of global collective behavior. . PNAS 118:(27):e2025764118 [Crossref] [Google Scholar]
- Bednar J, Page SE. 2018.. When order affects performance: culture, behavioral spillovers, and institutional path dependence. . Am. Political Sci. Rev. 112:(1):82–98 [Crossref] [Google Scholar]
- Bender EM, Gebru T, McMillan-Major A, ShmitchellS. 2021.. On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 610–23. New York:: ACM [Google Scholar]
- Beniger J. 1986.. The Control Revolution: Technological and Economic Origins of the Information Society. Cambridge, MA:: Harvard Univ. Press [Google Scholar]
- Benjamin R. 2019.. Race After Technology: Abolitionist Tools for the New Jim Code. New York:: Wiley [Google Scholar]
- Berk RA. 2021.. Artificial intelligence, predictive policing, and risk assessment for law enforcement. . Annu. Rev. Crim. 4::209–37[Crossref] [Google Scholar]
- Blodgett SL, Barocas S, Daumé H III, Wallach H. 2020.. Language (technology) is power: a critical survey of “bias” in NLP. . arXiv:2005.14050 [cs.CL]
- Bommasani R, Hudson DA, Adeli E, Altman R, Arora S, et al. 2021.. On the opportunities and risks of foundation models. . arXiv:2108.07258 [cs.LG]
- Bowker GC, Star SL. 2000.. Sorting Things Out: Classification and Its Consequences. Cambridge, MA:: MIT Press [Google Scholar]
- boyd d. 2010.. Social network sites as networked publics: affordances, dynamics, and implications. . In A Networked Self: Identity, Community, and Culture on Social Network Sites, ed. Z Papacharissi , pp. 47–66. London:: Routledge[Google Scholar]
- Brinkmann L, Baumann F, Bonnefon JF, Derex M, Müller TF, et al. 2023.. Machine culture. . Nat. Hum. Behav. 7:(11):1855–68 [Crossref] [Google Scholar]
- Budak C, Nyhan B, Rothschild DM, Thorson E, Watts DJ. 2024.. Misunderstanding the harms of online misinformation. . Nature 630:(8015):45–53[Crossref] [Google Scholar]
- Burrell J, Fourcade M. 2021.. The society of algorithms. . Annu. Rev. Sociol. 47::213–37[Crossref] [Google Scholar]
- Calvino I. 2012.. Il Castello dei Destini Incrociati. Milan:: Ed. Mondadori [Google Scholar]
- Caplan R, boyd d. 2018.. Isomorphism through algorithms: institutional dependencies in the case of Facebook. . Big Data Soc. 5:(1). https://doi.org/10.1177/2053951718757253 [Crossref] [Google Scholar]
- Chiang T. 2023.. ChatGPT is a blurry JPEG of the Web. . New Yorker, Febr. 9 [Google Scholar]
- Chouldechova A. 2017.. Fair prediction with disparate impact: a study of bias in recidivism prediction instruments. . Big Data 5:(2):153–63[Crossref] [Google Scholar]
- Coalit. Indep. Technol. Res. 2024.. About us. Mission Statem., Coalit. Indep. Technol. Res., https://independenttechresearch.org/about-us/#about-us-mission [Google Scholar]
- Coase RH. 1937.. The nature of the firm. . Economica 4:(16):386–405 [Crossref] [Google Scholar]
- Coppock A. 2023.. Persuasion in Parallel: How Information Changes Minds About Politics. Chicago:: Univ. Chicago Press [Google Scholar]
- Costello TH, Pennycook G, Rand D. 2024.. Durably reducing conspiracy beliefs through dialogues with AI. . PsyArXiv xcwdn. https://doi.org/10.31234/osf.io/xcwdn [Google Scholar]
- Covington P, Adams J, Sargin E. 2016.. Deep neural networks for YouTube recommendations. . In Proceedings of the 10th ACM Conference on Recommender Systems, pp. 191–98. New York:: ACM [Google Scholar]
- Cronon W. 1991.. Nature’s Metropolis: Chicago and the Great West. New York:: Norton [Google Scholar]
- Cuéllar MF, Huq AZ. 2022.. Artificially intelligent regulation. . Daedalus 151:(2):335–47 [Crossref][Google Scholar]
- Dastin J. 2018.. Insight—Amazon scraps secret AI recruiting tool that showed bias against women. . Reuters, Oct. 11. https://www.reuters.com/article/world/insight-amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK0AG [Google Scholar]
- Davies D. 2024.. The Unaccountability Machine: Why Big Systems Make Terrible Decisions—and How The World Lost Its Mind. London:: Profile[Google Scholar]
- Dewey J. 1927.. The Public and Its Problems. New York:: Holt [Google Scholar]
- Dodge J, Sap M, Marasović A, Agnew W, Ilharco G, et al. 2021.. Documenting large webtext corpora: a case study on the Colossal Clean Crawled Corpus. . arXiv:2104.08758 [cs.CL]
- Dunleavy P, Hood C. 1994.. From old public administration to new public management. . Public Money Manag. 14:(3):9–16 [Crossref][Google Scholar]
- Eliassi-Rad T. 2024.. Just machine learning. Talk presented at Santa Fe Institute, June 4. https://www.youtube.com/watch?v=JuONmGtAoIY[Google Scholar]
- Engstrom DF, Ho DE, Sharkey CM, Cuéllar MF.2020.. Government by algorithm: artificial intelligence in federal administrative agencies. Public Law Res. Pap. 20-54 , NYU Sch. Law, New York: [Google Scholar]
- Eno B. 1976.. Generating and organizing variety in the arts. . Studio Int. 192:(984):279–83 [Google Scholar]
- Eur. Comm. 2024.. The Digital Services Act. Fact Sheet, Eur. Comm., Brussels:. https://commission.europa.eu/strategy-and-policy/priorities-2019-2024/europe-fit-digital-age/digital-services-act_en[Google Scholar]
- Farrell H, Fourcade M. 2023.. The moral economy of high-tech modernism. . Daedalus 152:(1):225–35 [Crossref] [Google Scholar]
- Farrell H, Gopnik A, Shalizi C, Evans J. 2025.. Large AI models are cultural and social technologies. . Science 387:(6739):115356[Crossref] [Google Scholar]
- Farrell H, Shalizi C. 2023.. Artificial intelligence is a familiar-looking monster. . The Economist, June 21. https://www.economist.com/by-invitation/2023/06/21/artificial-intelligence-is-a-familiar-looking-monster-say-henry-farrell-and-cosma-shalizi[Google Scholar]
- Flack JC. 2017.. Coarse-graining as a downward causation mechanism. . Philos. Trans. R. Soc. A375:(2109):20160338 [Crossref] [Google Scholar]
- Fourcade M, Farrell H. 2024.. Large language models will upend human rituals. . The Economist, Sept. 4. https://www.economist.com/by-invitation/2024/09/04/large-language-models-will-upend-human-rituals [Google Scholar]
- Fourcade M, Gordon J. 2020.. Learning like a state: statecraft in the digital age. . J. Law Political Econ. 1:(1):78–108 [Google Scholar]
- Fourcade M, Healy K. 2024.. The Ordinal Society. Cambridge, MA:: Harvard Univ. Press [Google Scholar]
- Fourcade M, Johns F. 2020.. Loops, ladders and links: the recursivity of social and machine learning. . Theory Soc. 49:(5):803–32 [Crossref][Google Scholar]
- Gallegos IO, Rossi RA, Barrow J, Tanjim MM, KimS, et al. 2024.. Bias and fairness in large language models: a survey. . Comput. Linguist. 50:(3):1097–179 [Crossref] [Google Scholar]
- Gilman N, Cerveny B. 2023.. Tomorrow’s democracy is open source. . NOEMA, Sept. 12. https://www.noemamag.com/tomorrows-democracy-is-open-source [Google Scholar]
- Gillespie T. 2018.. Custodians of the Internet: Platforms, Content Moderation, and the Hidden Decisions That Shape Social Media. New Haven, CT:: Yale Univ. Press [Google Scholar]
- Goldstein JA, Chao J, Grossman S, Stamos A, Tomz M. 2024.. How persuasive is AI-generated propaganda?. PNAS Nexus 3:(2):pgae034[Crossref] [Google Scholar]
- Gonzalez A, Matias N. 2024.. Measuring the mental health of content reviewers, a systematic review. . Preprint, arXiv:2502.00244v1 [cs.CY] [Google Scholar]
- Grimmer J, Roberts ME, Stewart BM. 2021.. Machine learning for social science: an agnostic approach. . Annu. Rev. Political Sci. 24::395–419[Crossref] [Google Scholar]
- Harari YN. 2018.. Why technology favors tyranny. . The Atlantic, Oct. 15 [Google Scholar]
- Hayek FA. 1945.. The use of knowledge in society. . Am. Econ. Rev. 35:(4):519–30 [Google Scholar]
- Healy K. 2016.. SASE panel on the moral economy of technology. Talk presented at Univ. Calif., Berkeley:, June 28. https://kieranhealy.org/blog/archives/2016/06/28/sase-panel-on-the-moral-economy-of-technology [Google Scholar]
- Hong L, Page SE. 2004.. Groups of diverse problem solvers can outperform groups of high-ability problem solvers. . PNAS 101:(46):16385–89[Crossref] [Google Scholar]
- Horowitz M, Lin-Greenberg E. 2022.. Algorithms and influence: artificial intelligence and crisis decision-making. . Int. Stud. Q. 66:(4):sqac069[Crossref] [Google Scholar]
- Jarrell R. 1941.. Kafka’s tragi-comedy. . Kenyon Rev. 3::116–19 [Google Scholar]
- Johns F. 2021.. Governance by data. . Annu. Rev. Law Soc. Sci. 17::53–71 [Crossref] [Google Scholar]
- Kaminski ME, Urban JM. 2021.. The right to contest AI. . Columbia Law Rev. 121:(7):1957–2048[Google Scholar]
- Kleinberg J, Ludwig J, Mullainathan S, Rambachan A. 2018.. Algorithmic fairness. . Am. Econ. Assoc. Pap. Proc. 108::22–27 [Google Scholar]
- Kozlowski AC, Taddy M, Evans JA. 2019.. The geometry of culture: analyzing the meanings of class through word embeddings. . Am. Sociol. Rev. 84:(5):905–49 [Crossref] [Google Scholar]
- Kreps S, Kriner DL. 2024.. The potential impact of emerging technologies on democratic representation: evidence from a field experiment. . New Media Soc. 26:(12):6918–37 [Crossref][Google Scholar]
- Landemore H. 2021.. Open democracy and digital technologies. digital technology and democratic theory. . In Digital Technology and Democratic Theory, ed. L Bernholz, H Landemore, R Reich , pp. 62–89. Chicago:: Univ. Chicago Press [Google Scholar]
- Lazar S. 2024.. Governing the algorithmic city. . arXiv:2410.20720 [cs.CY]
- Lindblom CE. 2002.. The Market System: What It Is, How It Works, and What to Make of It. New Haven, CT:: Yale Univ. Press [Google Scholar]
- Longpre S, Mahari R, Lee A, Lund C, Oderinwale H, et al. 2024.. Consent in crisis: the rapid decline of the AI data commons. . arXiv:2407.14933 [cs.CL]
- Marchi M, Soatto S, Chaudhari P, Tabuada P.2024.. Heat death of generative models in closed-loop learning. . arXiv:2404.02325 [cs.LG]
- Matias JN. 2019a.. The civic labor of volunteer moderators online. . Soc. Media Soc. 5:(2). https://doi.org/10.1177/2056305119836778 [Google Scholar]
- Matias JN. 2019b.. Preventing harassment and increasing group participation through social norms in 2,190 online science discussions. . PNAS116:(20):9785–89 [Crossref] [Google Scholar]
- Matias JN. 2023.. Humans and algorithms work together—so study them together. . Nature 617:(7960):248–51 [Crossref] [Google Scholar]
- Mayntz R. 2009.. New challenges to governance theory. . In Governance as Social and Political Communication, ed. H Bang , pp. 27–40. Manchester, UK:: Manchester Univ. Press [Google Scholar]
- McElheran K, Li JF, Brynjolfsson E, Kroff Z, Dinlersoz E, et al. 2024.. AI adoption in America: who, what, and where. . J. Econ. Manag. Strategy33:(2):375–415 [Crossref] [Google Scholar]
- Mitchell M. 2019.. Artificial Intelligence: A Guide for Thinking Humans. New York:: Farrar, Straus & Giroux [Google Scholar]
- Mitchell M. 2023.. How do we know how smart AI systems are?. Science 381:(6654):eadj5957[Crossref] [Google Scholar]
- Morucci M, Spirling A. 2024.. Model complexity for supervised learning: why simple models almost always work best, and why it matters for applied research. Work. Pap., Michigan State Univ., East Lansing, MI:. https://arthurspirling.org/documents/MorucciSpirling_JustDoOLS.pdf [Google Scholar]
- Munger K. 2024.. The YouTube Apparatus. New York:: Cambridge Univ. Press [Google Scholar]
- Nezhurina M, Cipolina-Kun L, Cherti M, Jitsev J.2024.. Alice in Wonderland: simple tasks showing complete reasoning breakdown in state-of-the-art large language models. . arXiv:2406.02061 [cs.LG]
- Nguyen CT. 2021.. How Twitter gamifies communication. . In Applied Epistemology, ed. J Lackey , pp. 410–36. New York:: Oxford Univ. Press[Google Scholar]
- Noble SU. 2018.. Algorithms of Oppression: How Search Engines Reinforce Racism. New York:: NYU Press [Google Scholar]
- North DC. 1990.. Institutions, Institutional Change and Economic Performance. New York:: Cambridge Univ. Press [Google Scholar]
- Oduro S, Kneese T. 2024.. AI Governance Needs Sociotechnical Expertise: Why the Humanities and Social Sciences Are Critical to Government Efforts. New York:: Data Soc. [Google Scholar]
- Perrin AJ, McFarland K. 2011.. Social theory and public opinion. . Annu. Rev. Sociol. 37::87–107[Crossref] [Google Scholar]
- Peters G. 2012.. Governance as political theory. . In The Oxford Handbook of Governance, ed. D Levi-Faur , pp. 19–32. New York:: Oxford Univ. Press [Google Scholar]
- Polanyi M. 1966.. The Tacit Dimension. New York:: Doubleday [Google Scholar]
- Pomerantsev P. 2014.. Nothing Is True and Everything Is Possible: Adventures in Modern Russia. London:: Faber & Faber [Google Scholar]
- Prior M. 2007.. Post-Broadcast Democracy: How Media Choice Increases Inequality in Political Involvement and Polarizes Elections. New York:: Cambridge Univ. Press [Google Scholar]
- Queneau R. 1961.. Cent mille milliards de poèmes. Paris:: Gallimard [Google Scholar]
- Radford A, Wu J, Child R, Luan D, Amodei D, Sutskever I. 2019.. Language models are unsupervised multitask learners. Work. Pap., OpenAI, San Francisco:. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf [Google Scholar]
- Rahimi A, Recht B. 2017.. NIPS 2017 Test-of-Time Award presentation. Talk presented at 31st International Conference on Neural Information Processing Systems, Long Beach, CA:. https://www.youtube.com/watch?v=ORHFOnaEzPc [Google Scholar]
- Ramani A, Wang Z. 2023.. Why transformative artificial intelligence is really, really hard to achieve. . The Gradient, June 26. https://thegradient.pub/why-transformative-artificial-intelligence-is-really-really-hard-to-achieve [Google Scholar]
- Reich R, Sahami M, Weinstein J. 2021.. System Error: Where Big Tech Went Wrong and How We Can Reboot. New York:: HarperCollins [Google Scholar]
- Resnik P. 2024.. Large language models are biased because they are large language models. . arXiv:2406.13138 [cs.CL]
- Roberts M. 2018.. Censored: Distraction and Diversion Inside China’s Great Firewall. Princeton, NJ:: Princeton Univ. Press [Google Scholar]
- Rothschild DM, Malhotra N. 2014.. Are public opinion polls self-fulfilling prophecies?. Res. Politics 1:(2). https://doi.org/10.1177/2053168014547667 [Crossref] [Google Scholar]
- Sanders N, Schneier B, Eisen N. 2024.. How public AI can strengthen democracy. . Brookings, March 4. https://www.brookings.edu/articles/how-public-ai-can-strengthen-democracy/ [Google Scholar]
- Schwartzberg M. 2015.. Epistemic democracy and its challenges. . Annu. Rev. Political Sci. 18::187–203 [Crossref] [Google Scholar]
- Scott J. 1998.. Seeing Like a State: How Certain Schemes To Improve the Human Condition Have Failed. New Haven, CT:: Yale Univ. Press [Google Scholar]
- Shalizi C. 2010.. The singularity in our past light-cone. . Three-Toed Sloth Blog, Novemb. 28. http://bactra.org/weblog/699.html [Google Scholar]
- Shumailov I, Shumaylov Z, Zhao Y, Gal Y, Papernot N, Anderson R. 2024.. AI models collapse when trained on recursively generated data. . Nature 631:(8022):755–59 [Crossref][Google Scholar]
- Simon FM, Altay S, Mercier H. 2023.. Misinformation reloaded? Fears about the impact of generative AI on misinformation are overblown. . Harvard Kennedy Sch. Misinformation Rev. 4:(5). https://doi.org/10.37016/mr-2020-127 [Google Scholar]
- Simon HA. 2019 (1968).. The Sciences of the Artificial. Cambridge, MA:: MIT Press. , 3rd ed..[Google Scholar]
- Sobieszek A, Price T. 2022.. Playing games with AIs: the limits of GPT-3 and similar large language models. . Minds Mach. 32:(2):341–64 [Crossref][Google Scholar]
- Soper S. 2021.. Fired by bot at Amazon: ‘It’s you against the machine. .’ Bloomberg, June 28 [Google Scholar]
- Sourati J, Evans JA. 2023.. Accelerating science with human-aware artificial intelligence. . Nat. Hum. Behav. 7:(10):1682–96 [Crossref] [Google Scholar]
- Sperber D, Clément F, Heintz C, Mascaro O, Mercier H, et al. 2010.. Epistemic vigilance. . Mind Lang. 25:(4):359–93 [Crossref] [Google Scholar]
- Stanger A, Kraus J, Lim W, Millman-Perlah G, Schroeder M. 2024.. Terra incognita: the governance of artificial intelligence in global perspective. . Annu. Rev. Political Sci. 27::445–65[Crossref] [Google Scholar]
- Steinsson S. 2024.. Rule ambiguity, institutional clashes, and population loss: how Wikipedia became the last good place on the Internet. . Am. Political Sci. Rev. 118:(1):235–51 [Crossref][Google Scholar]
- Tessler MH, Bakker MA, Jarrett D, Sheahan H, Chadwick MJ, et al. 2024.. AI can help humans find common ground in democratic deliberation. . Science 386:(6719):adq2852 [Crossref] [Google Scholar]
- Thelen K. 2025.. Attention, Shoppers! American Retail Capitalism and the Origins of the Amazon Economy. Princeton, NJ:: Princeton Univ. Press[Google Scholar]
- Thompson EP. 1963.. The Making of the English Working Class. New York:: Vintage [Google Scholar]
- Tilly C. 1984.. Big Structures, Large Processes, Huge Comparisons. New York:: Russell Sage Found. [Google Scholar]
- Weber M. 1968.. Economy and Society. New York:: Bedminster [Google Scholar]
- Weizenbaum J. 1966.. ELIZA—a computer program for the study of natural language communication between man and machine. . Commun. ACM 9:(1):36–45 [Crossref] [Google Scholar]
- Wiener N. 2019.. Cybernetics or Control and Communication in the Animal and the Machine. Cambridge, MA:: MIT Press [Google Scholar]
- Wolf Y, Wies N, Avnery O, Levine Y, Shashua A.2023.. Fundamental limitations of alignment in large language models. . arXiv:2304.11082 [cs.CL]
- Yates J. 1993.. Control through Communication: The Rise of System in American Management. Baltimore, MD:: Johns Hopkins Univ. Press[Google Scholar]
- York JC, Zuckerman E. 2019.. Moderating the public sphere. . In Human Rights in the Age of Platforms, ed. RF Jørgensen , pp. 143–61. Cambridge, MA:: MIT Press [Google Scholar]
- Yiu E, Kosoy E, Gopnik A. 2024.. Transmission versus truth, imitation versus innovation: what children can do that large language and language-and-vision models cannot (yet). . Perspect. Psychol. Sci. 19:(5):874–83 [Crossref][Google Scholar]
- Zhang E, Zhu V, Saphra N, Kleiman A, Edelman BL, et al. 2024.. Transcendence: Generative models can outperform the experts that train them. . arXiv:2406.11741 [cs.LG]
- Zhang J. 2024.. ChatGPT as the marketplace of ideas: Should truth-seeking be the goal of AI content governance?. arXiv:2405.18636 [cs.CY]
- Zuboff S. 2019.. The Age of Surveillance Capitalism. London:: Profile [Google Scholar]
- Zuckerman E. 2014.. New media, new civics?. Policy Internet 6:(2):151–68 [Crossref] [Google Scholar]